Lifecycle
This section serves as an overview of TIM Detect's jobs. It will explain their main inputs, components and outputs, how they differentiate from each other and their destined usage. Currently, six methods (types of jobs) are in play in this lifecycle:
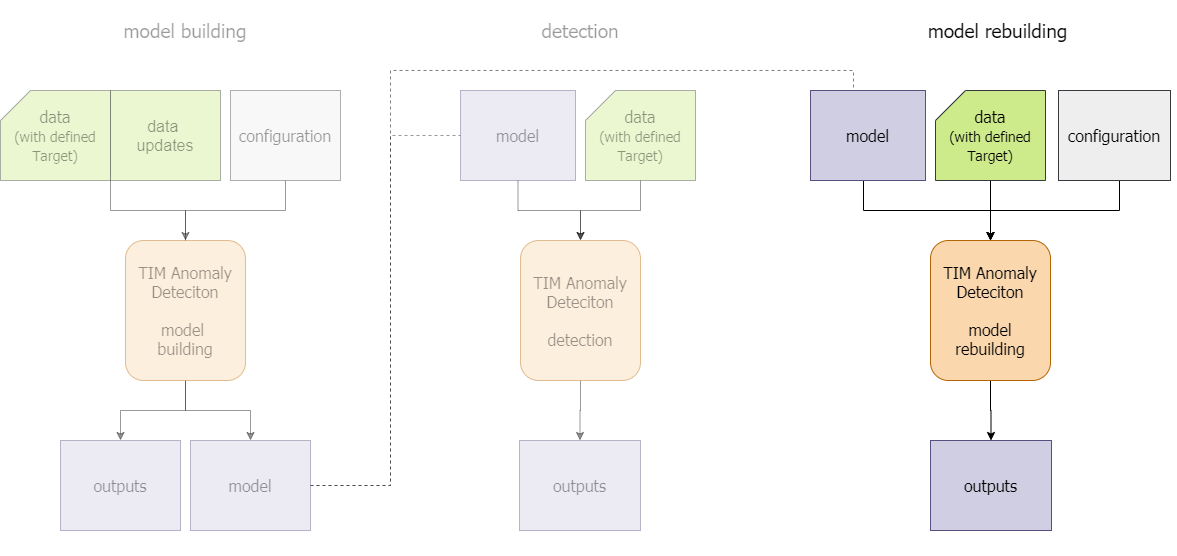
The following sections explore them in more detail. The image below gives a schematic overview of the first two methods.
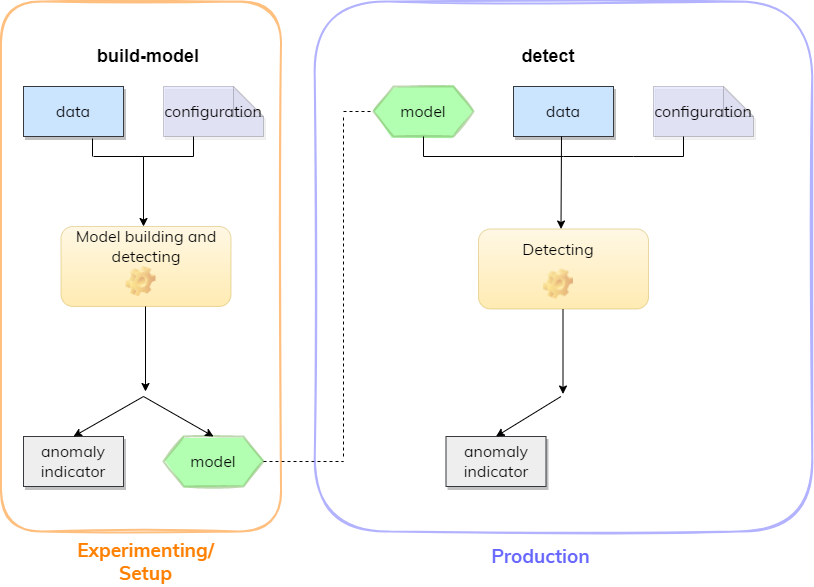
To build and apply anomaly detection models, TIM only requires data and for the kpi-driven approach a defined KPI. Having a reasonable model is crucial for finding the right anomalies. The most important things that affect the quality of the model can be divided into two categories:
- Math/Machine Learning: Here, the goal is to automatize the anomaly detection process on the data. This is related to things as feature expansion, feature reduction and the creation of the anomaly indicator. For the kpi-driven approach, this also includes the selection of normal behavior and anomalous behavior models and their parameters. As per the goal, TIM can automate this part of the work.
- Domain-specifics: Here, the goal is to design the experiment in the most reasonable way for the specific domain and problem at hand. This is related to the data itself: defining the KPI (for the kpi-driven approach), choosing the right influencers, and if needed adjusting the update times of the data. It's also related to the sensitivity and related parameters, such as the detection perspectives for the kpi-driven approach. For the system-driven approach, this also includes the anomaly indicator window. Even though TIM has an automatic, default configuration mode, a domain expert adjusting these settings can result in fewer false positives or false negatives.
Model building
The lifecycle of a model built by TIM Detect starts with model building. This section describes what this entails exactly. The model building method is supported in all approaches the kpi-driven approach, the system-driven approach, the outlier approach and the drift approach.
First, the data needs to be in the required format, a KPI needs to be determined on which anomalies should be detected and, if available, informative influencers that may affect the KPI should be included. The selection of the influencers and the period of the data that will be used for model building can significantly affect the results, so it's important to take these aspects into careful consideration. The model(s) will be built on historical data, and based on that model new data can then be evaluated as it becomes available.
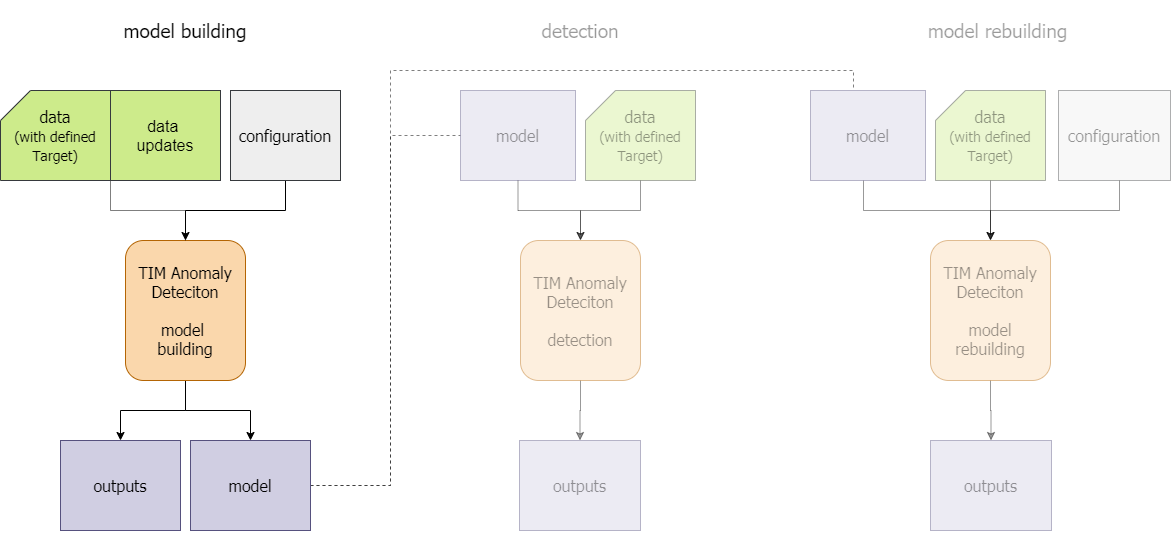
To have a model meet the relevant domain specifics, the data updates need to be defined, as it indicates to TIM what the data will look like at the moment of detection. By default, TIM expects the data to be aligned, which is often the case in anomaly detection. The detection perspectives provide a way for the user to adapt the anomaly detection to their preferences, while the sensitivity parameter which allows for fine-tuning of the sensitivity to potential anomalies based on the business's risk profile. It is also possible to let TIM find a reasonable sensitivity in an automatic way.
A model building task returns not only a model, but also other outputs. The most important one is often the anomaly indicator; its values are returned for the entire model building period. Analysis of the results helps the user to decide if the model was configured appropriately.
After analyzing the results, TIM's performance can be tweaked by adjusting the configuration of both the domain-specifics and the mathematical settings. Once a model produces satisfying results, it can be used for detection every time new data becomes available.
Detection
Most often, once a suitable model has been built the next step is to use it for real-time detection. With an existing model (a parent job) and new data, TIM Detect is all set up to perform anomaly detection. The detection method too is supported in all approaches the kpi-driven approach, the system-driven approach, the outlier approach and the drift approach.
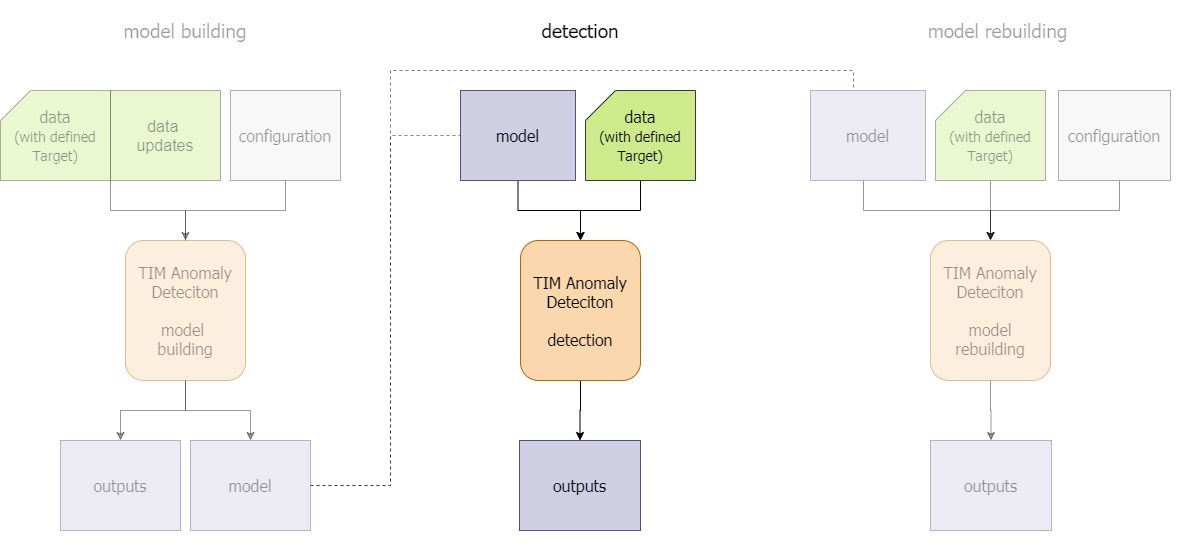
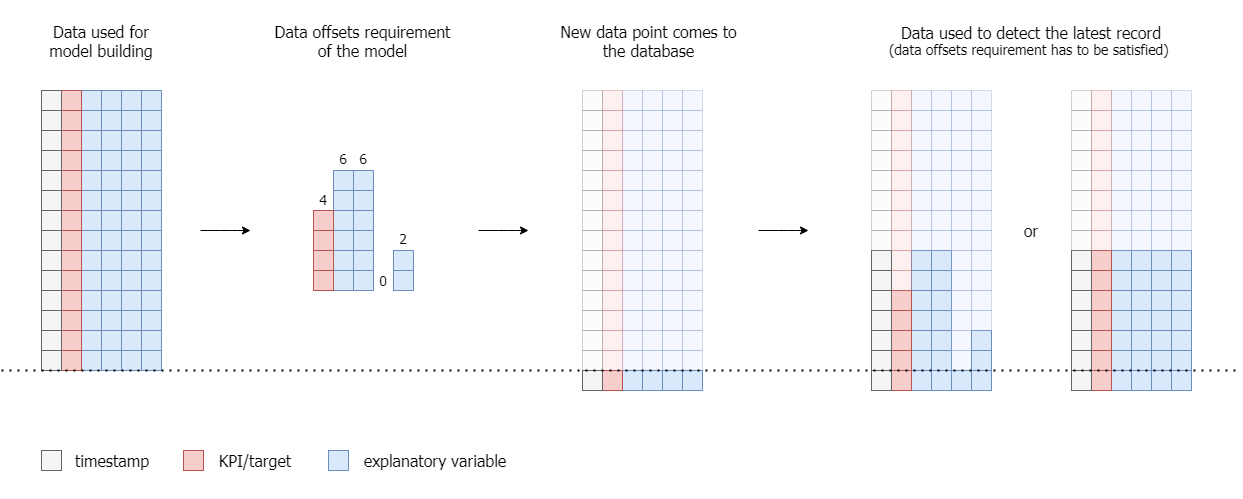
When detecting with an existing model, the data must be in the same format as it was when building the model. For more information, consult the section about the required data properties. To make detection possible for the chosen time period, at least that amount of data that is required by the underlying model needs to be provided (see the image below). If this is not the case, for the observations missing at least one of the expected inputs no output can be calculated by the model. The length of the required data often differs between influencers, depending on both the configured minimal availability and the relevance of the influencer and influencer offsets.
Model rebuilding
A typical approach in automated model building is to find and tune the best model possible, store it, and then interpret it with new data to make a detection. That's the process described in the previous two steps, model building and detection. After a while, the model risks becoming out of touch with the underlying processes and might start to produce deviating results, caused by gradual or even structural changes in the underlying processes themselves. To overcome this, the model can be rebuilt on new data, either periodically or based on some manual trigger. Model rebuilding can also be useful for tuning the domain specifics (perspectives/sensitivities) or updating the model to new expected minimal availabilities of influencers.
The model rebuilding method is currently only supported in the kpi-driven approach.
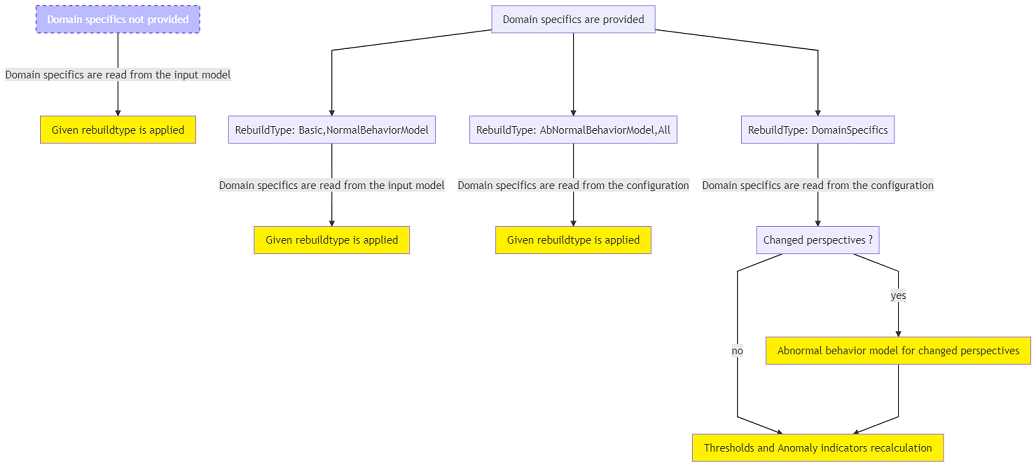
To rebuild a model, the model itself (the parent job) and new data to train on are required. The rebuilding configuration can be set, including domain specifics for overriding the configuration from the input model and the rebuild type determining which part(s) of the model should be rebuilt or reconfigured. Then, depending on the chosen configuration, a specific rebuild functionality is applied. The model rebuilding process is visualized in the following schema:
Root cause analysis (rca)
Often, it is beneficial to determine the underlying cause behind a specific outcome: why is a particular observation identified as anomalous, or why is it not? In other words, why is the outputed normal behavior the way it is? RCA assists the user in addressing these inquiries by uncovering the factors that drive the normal behavior in the results of a specific job. The RCA output provides precise information on the contribution of each influencer and each term to the normal behavior value (nominal view), as well as decomposes the model to enhance the geometrical understanding of its gradual construction (relative view). Further information about RCA and its outputs can be found in the dedicated documentation section.
The rca method is currently only supported in the kpi-driven approach.
What-if analysis
Once a user has started building models, it's just a matter of time before questions are raised among the lines of "what would happen if...?". Figuring out the answer to this is done by what-if analysis. This type of analysis empowers users to analyze different scenarios by changing input variables and observing the adjusted outputs. This can help in recognizing the impact of individual variables on the KPI variable and thus make the process more efficient or reveal critical situations. More information about what-if analysis and what it entails can be found in the dedicated documentation section.
The what-if analysis method is supported in both the kpi-driven approach and the system-driven approach.
Model uploading
TIM enables the uploading of a prebuilt model to another use case; this is accomplished by creating an upload-model job. Such a job can be created either by specifying the existing (re)build-model job that contains the model or by uploading the model itself after it was previously downloaded.
The model uploading method is currently only supported in the kpi-driven approach.
The upload-model job can upload the model to a use case that is associated with a different dataset than the one used to build the model. However, the new dataset has to be compatible with the model, meaning it needs to have the same column names, sampling rate... as the original dataset used for model building.
An upload-model job can be used as a parent job for running detection or model rebuilding jobs.