System-driven detection
This part of the documentation dives into TIM's capabilities for anomaly detection with a system-driven approach. The following sections can be explored to build up a comprehensive understanding of these capabilities:
- Configuration: all the available parameters that can be adjusted to the user's specific needs.
- Outputs: understand TIM's outputs.
Engine schema
TIM Detect's system-driven anomaly detection automates the anomaly detection process by automatically selecting configuration parameters, performing feature engineering and using the features to create the most appropriate model(s).
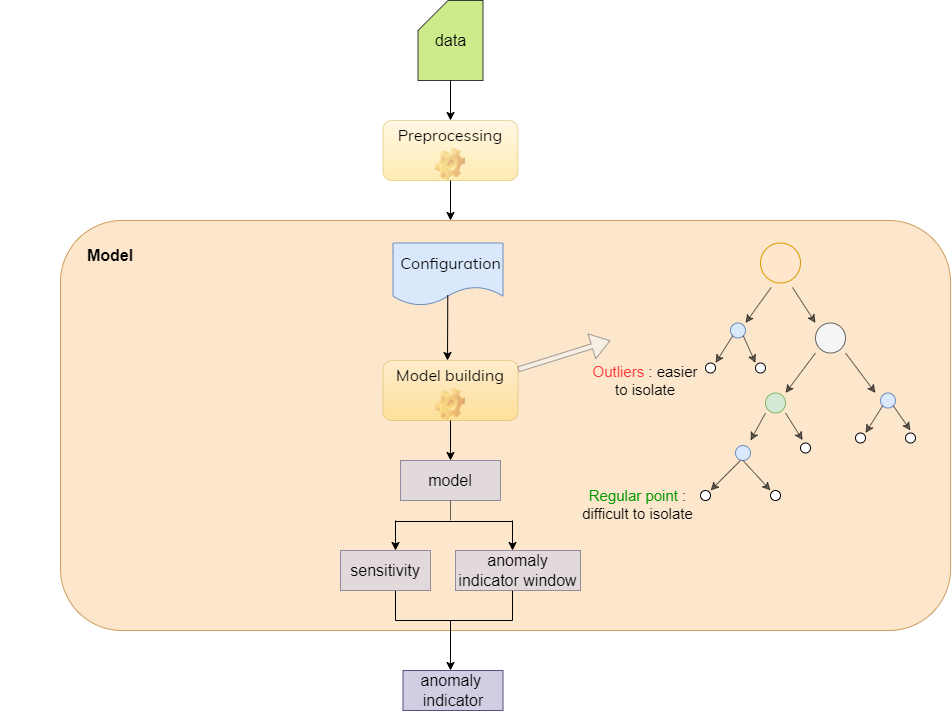
The above schema characterizes the model building process.
First, data is uploaded and preprocessing is applied. The data is typically unlabelled and contains mostly regular observations; thus, anomalies are rare.
Then the data - with the desired configuration settings - is used in the model building process; each data point gets its path length using the isolation process. The outcome of this process is the model.
Finally, the anomaly indicator is produced by utilizing the model and domain specifics, such as the sensitivity and anomaly indicator window. The resulting anomaly indicator contains values indicating to what extent a particular data point goes beyond what could be considered ‘normal’.