Sensitivity
An important setting in anomaly detection is the sensitivity to anomalies. It goes hand in hand with the anomaly indicator, which conveys the information about the extent to which the given observations are anomalous. Sensitivity comes into play to define the decision boundary, allowing the model to distinguish between anomalies and normal points. The real-world examples show that this decision is often ambiguous and depends on the use case, user, business risk profile etc.
Sensitivity is defined as the percentage of the (model building) data that is expected to be anomalous. It indicates how often an anomaly alert is triggered in the building data. For example, a sensitivity of 3% considers the 3% most anomalous observations in the data to be anomalies; the user would have been alerted in this 3% of the data.
It is recommended to choose the model building data with as few anomalies as possible and with sufficient length allowing TIM to find the best possible model. If you have labelled data, this can be accomplished by omitting anomalous observations from the building data and setting the sensitivity to 0%. In this case, the model is not affected by anomalous points at all. Usually, you do not know which points are anomalous, however, in general, the percentage of anomalies should not exceed 5%. If it exceeds, supervised learning could be a more appropriate approach than anomaly detection.
Consider the following example to understand better the link between data, sensitivity, anomaly indicator, and threshold. Let's assume we have a univariate problem - a KPI variable without any influencers. The model building period with the KPI is depicted in the image below.
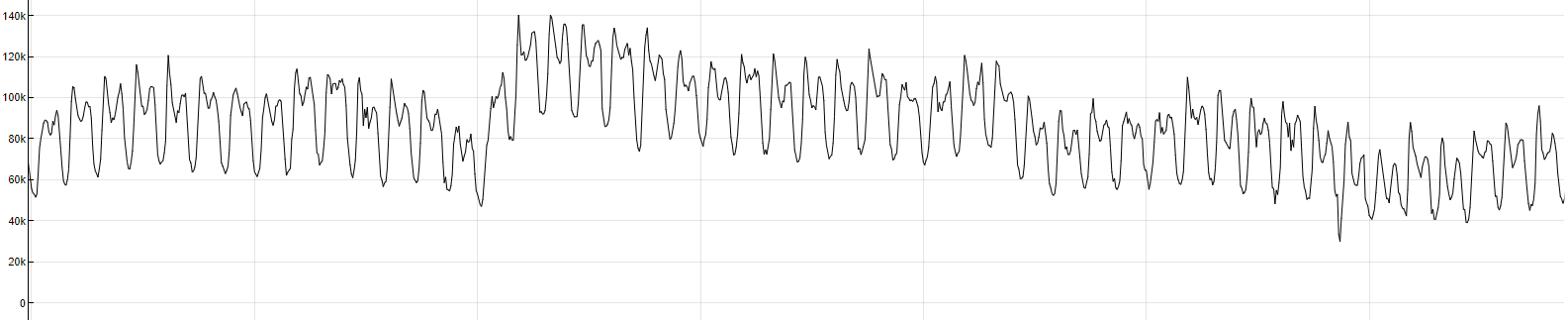
Running the anomaly detection model building with the sensitivity parameter set to 0% results in an anomaly indicator that is below the threshold on the entire building period.

Running the model building with 5% sensitivity causes the anomaly indicator to exceed the threshold exactly on 5% of model building observations. Note that by changing the sensitivity, the threshold remains the same (equal to 1) but the anomaly indicator is rescaled.

Remember that by setting the sensitivity parameter, you estimate what percentage of anomalies you expect on a model building period. It is also true that the higher the sensitivity the more anomalies on the out of sample period (or when using the model in production). However, it does not mean that the percentage of anomalies on the out of sample period will be similar to the percentage of anomalies on the in-sample period.
One detection perspective – one sensitivity parameter
There are several detection perspectives that can be used for building a detection model. During the model building, each perspective is processed independently leading to independent anomaly indicators as a result, see model building schema to learn more. Each perspective – anomaly indicator pair has its own sensitivity parameter that can be configured. The logic behind is the same as we describe in the previous subsection.
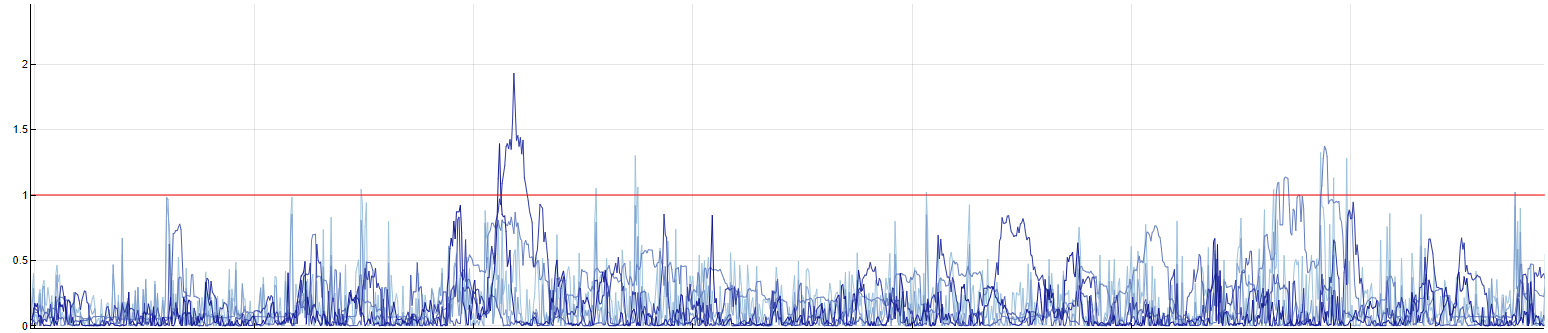
The visualization below shows an example of anomaly indicators that are returned after processing more detection perspectives in the model building. We say that an observation is anomalous if at least one of the anomaly indicators is above the threshold (=1). Here, all the sensitivity parameters were estimated automatically; see the following subsection.
Automatic sensitivity estimation
By default, the sensitivity parameters are estimated automatically.
Two major reasons for automatizing the sensitivities are:
- increase large scale potential
- in most of the cases, the number of anomalies is unknown
As we already know, sensitivity is a significant parameter in the anomaly detection process that has to be adjusted correctly as it affects how many anomalies are found. Finding the proper sensitivity can be tedious work in unlabeled data, which is often the case.
In case you would like to be more conservative (do not want to be alerted so often, only in most anomalous cases; false positives cost you significantly more than false negatives), or on contrary, your domain requires to be alerted more often (false negatives cost you significantly more than false positives) you can manually set the sensitivity to lower/ higher percentage.