The Problems TIM Detect Can Solve
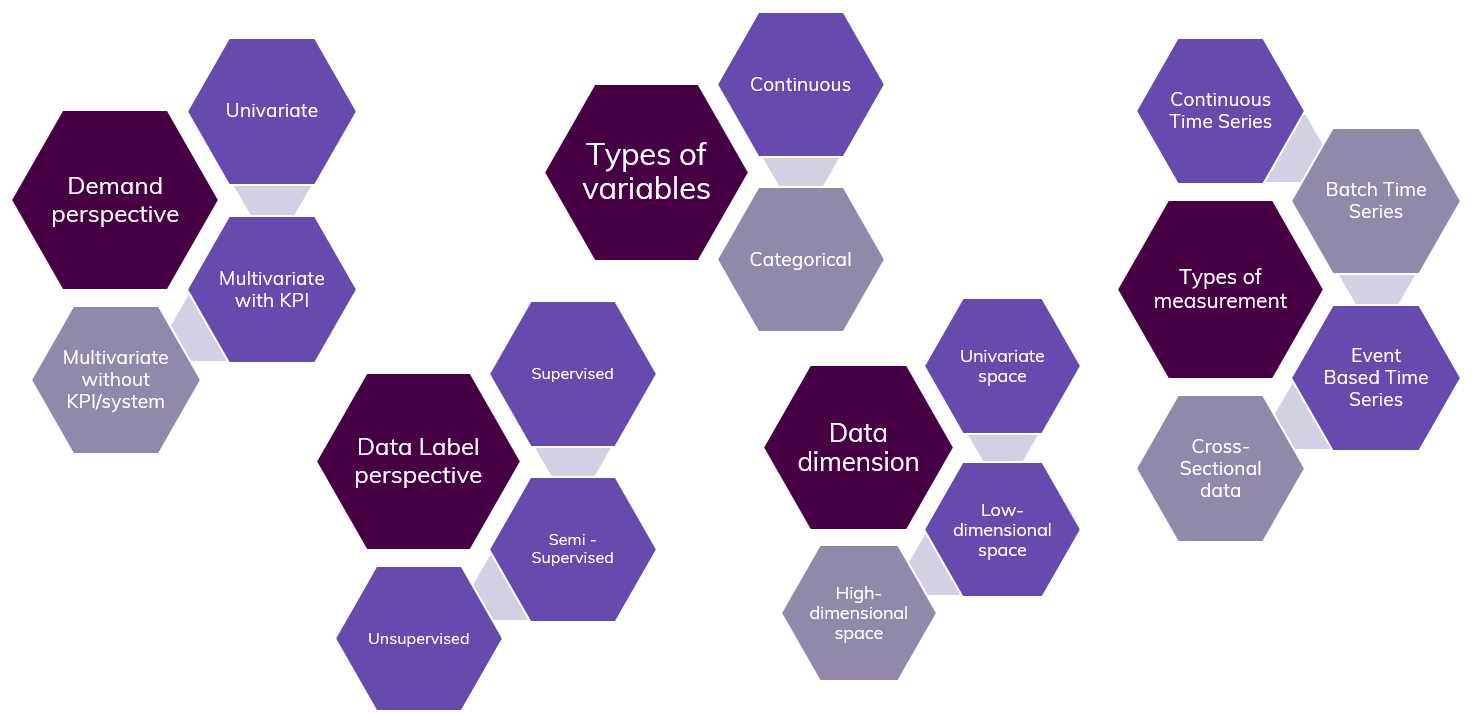
The term anomaly detection covers a broad field. The following figure shows anomaly detection tasks from different perspectives. The purple colour indicates criteria that TIM supports.
Desired result
Different anomaly detection efforts might have different desired results. The following types of anomaly detection:
- Univariate AD: searches for anomalies in each metric,
- System-driven AD with KPI: searches for anomalies in a defined KPI, which is a part of a system of different interacting attributes,
- System-driven AD without KPI: indicates how anomalous a system is as a whole at a given point in time.
Character of the data
Time series data represent a collection of observations of a single subject at different points in time. Generally, this evolution is measured at regular time intervals. Time series can be found in a variety of forms:
- Continuous-time series: regular snapshots of a continuous process,
- Batch time series: regular snapshots of a discontinuous process,
- Event-based time series: measurements relating to events that occur at discrete times, mostly irregularly.
- Cross-sectional data represent a collection of observations of multiple subjects (typically individuals, households, countries…) at the same point of time, or regardless of differences in time.
Character of the attributes
The attributes used in anomaly detection can be either continuous or categorical. Continuous attributes can take on an infinite amount of values, whereas categorical attributes can only take on a limited amount of different values, representing different categories.
Algorithm types
The algorithm used to detect anomalies needs to be adapted to the available data and the desired result. The following algorithm types are distinguished:
- Supervised algorithms: require a dataset in which all observations have been labeled as either "normal" or "anomalous". This involves training a classifier. (The key difference to many other classification problems is inherently the unbalanced nature of outlier detection);
- Semi-supervised algorithms: construct a model representing normal behavior from a given normal training data set and then test the likelihood that a test instance is generated by the learned model.
- Unsupervised algorithms: detect anomalies in an unlabeled test dataset under the assumption that the majority of the instances in the dataset are normal. It does so by looking for the instances that seem to fit the least to the remainder of the data set and are in this way the most anomalous.