Lifecycle
This section serves as an overview of the TIM Forecasting methods. It will explain their main inputs, components and outputs, how they differentiate from each other and their destined usage. Currently, seven methods (types of jobs) are in play in the lifecycle of TIM forecasting:
The following sections explore them in more detail. The image below gives a schematic overview of the first for methods.
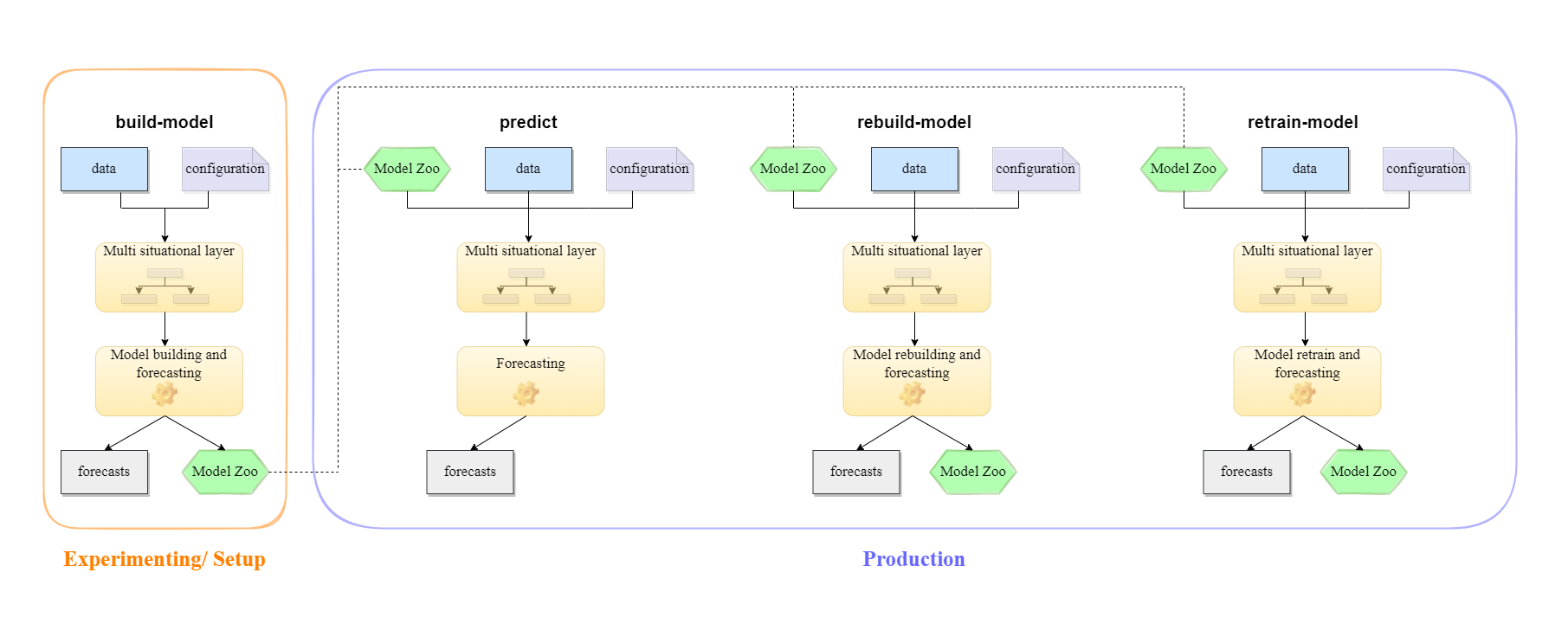
Model building
To build a reasonable model, TIM only needs training data and a configuration. Based on those, in its multi-situational layer TIM recognizes all situations requiring a seperate model. Then, for all of these situations, the model building is done on in-sample rows, and in-sample, out-of-sample and production forecasts are calculated. Thus, the main outputs of the build-model are those forecasts and the Model Zoo.
The optimal usage of this method is for setting up the model(s) to best fit the problem at hand. There are many available configuration parameters, so it is easy to experiment and evaluate backtesting results. Models are built from scratch, so there is a certainty that the models are as fresh as possible for all situations. Once the "optimal" Model Zoo is found, it can be used in production. The following two sections summarize how this is done.
Prediction
The production pipeline can be set up as soon as the desired Model Zoo is built. The fastest approach to do so is to use the predict method. This procedure utilizes all models included in the input Model Zoo, and attempts to apply them without building any new models or refreshing any old ones.
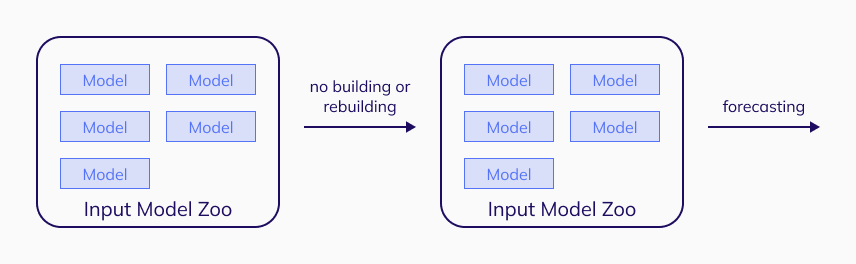
Only models that are a part of the input Model Zoo are used to make a forecast. Therefore, only a short period of data is needed to interpret these models and make predictions. The exact size required is defined by the "Data from" section of the Model Zoo. Thus, the calculation time of this method is very low.
The weakness of this process is that the responsibility to make sure that the Model Zoo can produce every required forecast is on the user. TIM cannot forecast situations for which there is no model in the Model Zoo. This can happen not only when changing the prediction horizon, but also due to missing data; both situations can trigger a need to rebuild a Model Zoo. Another disadvantage is that the models tend to become "old" or outdated after some time (depending on the problem) resulting in deteriorating accuracy. These challenges can be overcome by the rebuild-model method described in the next section.
Model rebuilding
This functionality offers the best routines for handling a production deployment. It solves the challenges with new situations and deteriorating accuracy without introducing the need to build all models from scratch.
As visualized, the inputs of this method are the Model Zoo, data and a configuration. Based on those, in its multi-situational layer TIM recognizes all situations. Then model rebuilding on in-sample rows is done - based on the rebuilding policy either only for new situations or also for the situations containing old models - and in-sample forecasts (for new models), out-of-sample forecasts and production forecasts are calculated. Thus, the main outputs of the rebuild-model method are those forecasts and the updated Model Zoo. Such an updated Model Zoo can be used again as input for another predict or rebuild-model job.
Model retraining
It is possible to update only the coefficients of the models in the Model Zoo while keeping the structure of the models as is. The advantage of this approach is that the models will not get outdated as with predict jobs yet will still be stable (the features used in the models will remain the same). TIM will recognize all situations to be forecasted and then find the most appropriate models in the Model Zoo and retrain them on the new data. TIM will generate all the features used in the model and fit new coefficients for them. Those retrained models will be used to calculate forecasts.
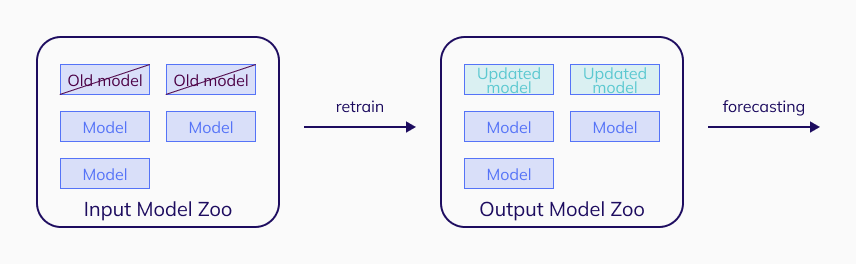
The data used for retraining should be long enough, since the new coefficients will be trained only on the data provided. Offsets and windows used in the models should be considered since as features may not be usable at the beginning of data and this may shorten the actual length of the data used in retraining.
No new models will be added to the Model Zoo; therefore the responsibility to make sure that the Model Zoo can produce every required forecast is on the user. If some situations are not present in the model, no new model will be trained for this situation, and it will not be forecasted.
Root cause analysis (rca)
Often, it is useful to determine the underlying cause behind a specific result: why is a particular forecasted value generated? How was the Model Zoo constructed? RCA assists the user in addressing these questions by examining the impact of each term on the forecast individually, both from a nominal perspective and a relative perspective. The RCA output provides precise information on the contribution of each predictor and each term to the forecasted value (nominal view), as well as decomposes the model to enhance the geometrical understanding of its gradual construction (relative view). More information about RCA and its outputs can be found in the dedicated documentation section.
What-if analysis
Once a user has started building models, it's just a matter of time before questions are raised among the lines of "what would happen if...?". Figuring out the answer to this is done by what-if analysis. This type of analysis empowers users to analyze different scenarios by changing input variables and observing the adjusted outputs. This can help in recognizing the impact of individual variables on the target variable and thus make the process more efficient or reveal critical situations. More information about what-if analysis and what it entails can be found in the dedicated documentation section.
Model uploading
TIM allows uploading a pre-built model to a use case by creating an upload-model job. Such a job can be created either by specifying an existing job that contains a model or by uploading a model that was previously downloaded from another job. The upload-model job can upload the model to a use case that is associated with a different dataset than the one used to build the model, however, the new dataset has to be compatible with the model (identical column names, sampling rate, etc.). An upload-model job can be used as a parent job for running prediction or model rebuilding jobs.