Updating data
It's in the nature of time-series data to evolve over time, and thus require frequent updates. Additionally, data analysis work is complex and sometimes it is desirable to alter existing data. Collaboration also involves frequent improvements and alterations of metadata to ensure an understanding is kept between collaborators. TIM is equipped for updating previously uploaded datasets.
Updating metadata
Dataset metadata such as the name and description can be updated without independent from updates to the actual data. The REST API documentation can be consulted for an up-to-date documentation of this functionality.
Adding a new dataset version
In essence, a dataset update is a PATCH operation, so for creating a new version only the data needs to change should be sent over. This includes additions as well as overwriting existing observations (for corrections and removals), but the data that is already present in the previous version does not have to be resent. All data that was part of the previous version and that has not been removed or altered in the update, is still part of the new version. Therefore, when retrieving this dataset version, that previous (unaltered) data will also be returned.
This section takes a deeper look at how to update datasets: what formats can be used, what source types are supported, and some examples of how does such an update looks like in practice.
Data format
Data can be differently formatted in different versions, as long as the same variables are present in the same order.
To update a dataset, observations from earlier versions should not be included in the data sent to TIM. Any observation (i.e. row with timestamp) to add should however contain the complete data, even if the dataset's data availability means some of the variables are already present for some of these timestamps in the previous version of the dataset. At least one row of new values should be sent during an update.
Source type
As explained in the section on uploading data, TIM supports uploading data from CSV files as well as from SQL tables. Both CSV files and SQL tables are also support for updating datasets. Additionally, there are no limitations on switching source type between versions; a dataset that was uploaded as a CSV file may be updated from an SQL table and vice versa.
CSV file
Correctly structured time-series data in a CSV file can be uploaded to update an existing, previously uploaded dataset in the TIM Platform. To do so, the user must identify the dataset in the TIM Repository that should be updated.
A user can provide additional configuration options to aide TIM in recognizing the characteristics of the dataset. For an up-to-date description of the available configuration options, the REST API documentation can be consulted.
SQL table
Correctly structured time-series data in a table in an SQL database can be uploaded to update an existing, previously uploaded dataset in the TIM Platform. To do so, the user must identify the dataset in the TIM Repository that should be updated. Currently supported databases include PostgreSQL, MySQL, MariaDB and SQL Server.
A user must provide certain data to identify the database and the (parts of the) table and to authenticate the connection. Additionally, the user can provide additional configuration options to aide TIM in recognizing the characteristics of the dataset and to customize what is uploaded. For an up-to-date description of the available configuration options (both the required and the optional settings), the REST API documentation can be consulted.
Data preview
It can be beneficial to first preview some rows of the (potentially filtered) SQL table before actually uploading it to the TIM Platform, to ensure the connection is made correctly and any customization and filtering is applied as intended. For this purpose, TIM DB provides the functionality to retrieve a preview of an SQL table without uploading anything.
Adding new observations
One use case for updating a dataset is adding new observations. When building models to get insights from time-series data, the same model could be used repeatedly with new data to continuously inform business decisions. Alternatively, one might want to rebuild models or even build new models when new data comes in, using this new and the old data. When time has passed, new data will be collected and should thus be appended to the existing dataset in the TIM Repository.
Example: Adding newly collected data
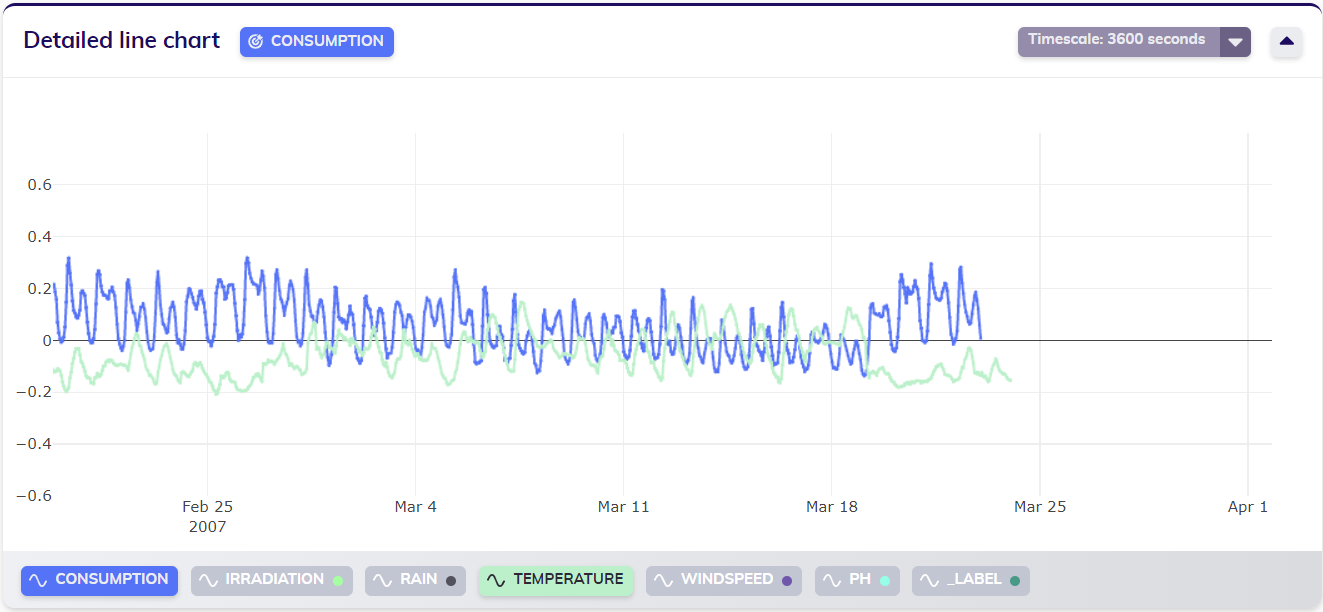
This example starts from a state in which the below dataset is already stored in the TIM Platform. As indicated in the line chart, the target variable of this dataset is available until March 22nd, 2007.
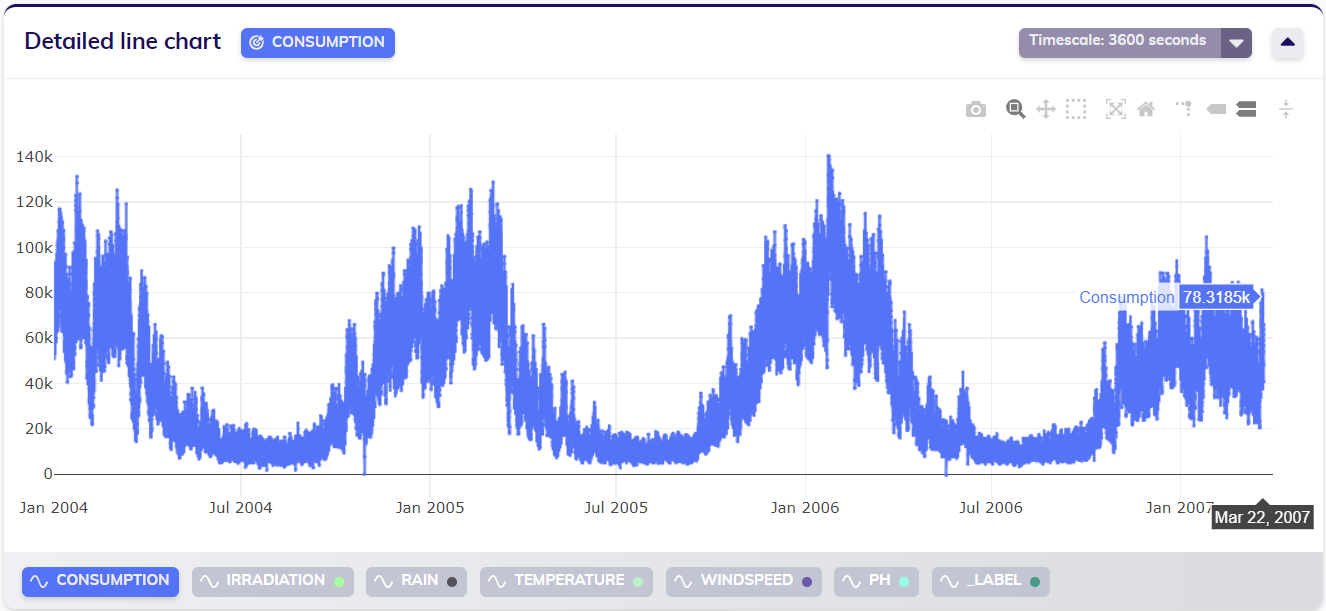
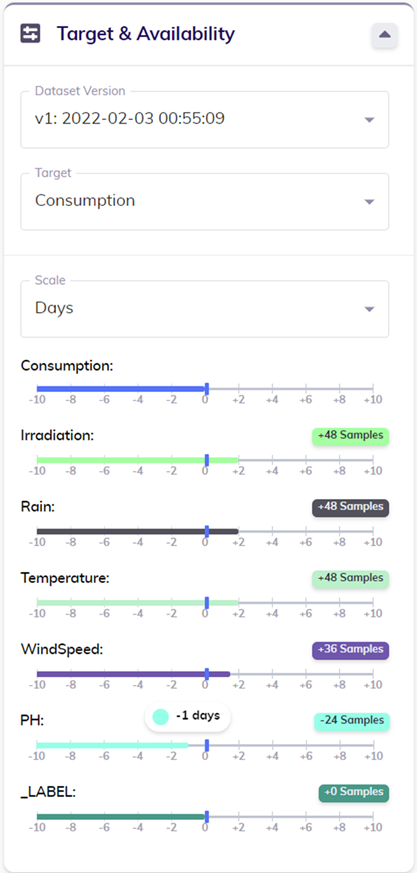
The data availability of this dataset (as shown below) however indicates that the variable with the earliest end is PH, which is only available up to 1 day before the end of the target variable. Therefore, assuming that all variables come in at the same pace, in the data sent to TIM full observations should be included starting March 21st, 2007.
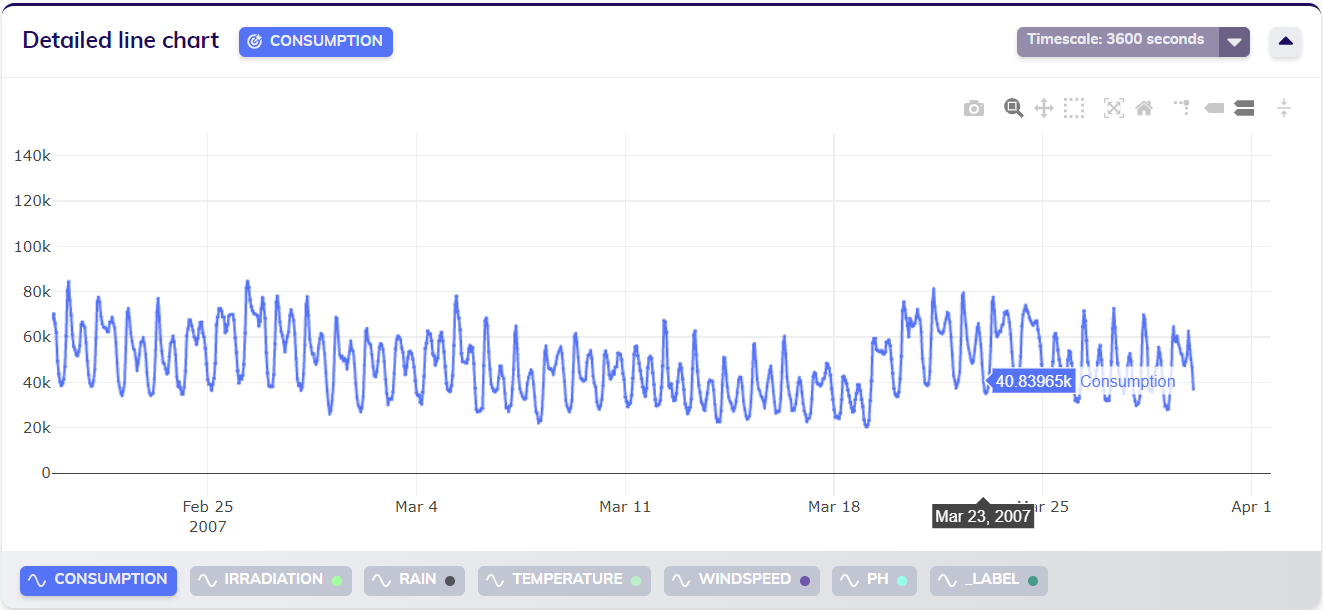
Updating the dataset with a week's worth of new data, starting with full observations from March 21st, 2007, effectively accomplishes the desired update, as shown in the line chart below.
Overwriting existing observations
TIM also supports overwriting existing observations. To do so, all the observations to overwrite should be completely included in the data sent to TIM. This means that even when only correcting/overwriting a single variable, the other variable values need to be present for the relevant observations too. This is because TIM also supports overwriting values with null, ex.g. when incorrect data has made its way into the dataset and cannot be corrected, and thus should be removed. Not including any value for a specific variable for any observation accomplishes this.
Example: Fixing incorrect data
This example starts from the same state as the previous one, in which the below dataset is already stored in the TIM Platform. In the line chart below, visual inspection of the normalized target variable and Temperature variable clearly show that something is wrong with the last few values of the temperature: they are orders of magnitude larger than the normal values of temperature earlier in the dataset.
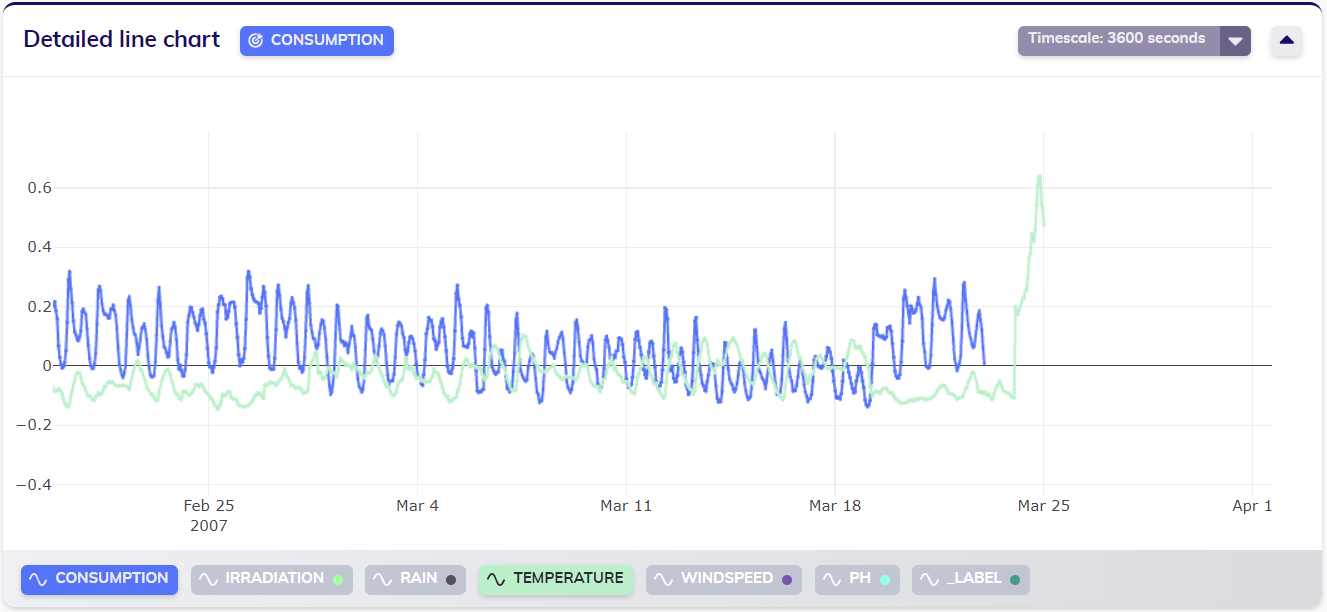
Correcting the values
Imagine that it's somehow possible to figure out that the variables are exactly a ten times what they normally should be. In this case, the user would want to overwrite the faulty temperature values with valid ones. To do so, the altered observations should be fully included in the data that is sent to TIM, including the values of the other variables which are already correct.
As shown in the line chart below, updating the dataset as described above indeed creates a version that looks more like expected.
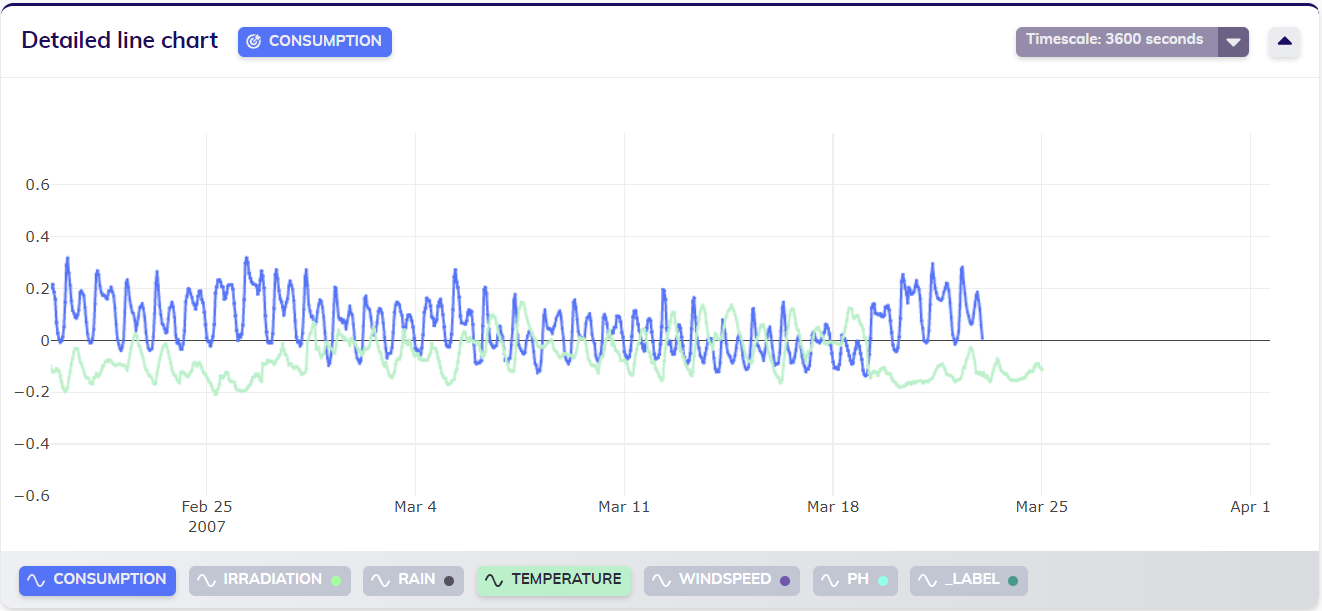
Removing the values
Imagine however, in the situation with the faulty temperatures it is not possible to figure out what the correct values should be. In this case, the user would still want to update the dataset, this time removing the faulty temperature values in the new version. This is done by overwriting them with null values, for which again the altered observations should be fully included in the data that is sent to TIM, including the values of the other variables which are already correct.