Workspaces
![]()
The work of a team is organized in workspaces, allowing to structure collaboration. A workspace serves typically as a silo to store use cases linked to a particular topic, e.g. one may create a workspace for all use casess related to predictive maintanance.
The default workspace
Each user's personal team contains a single workspace: the default workspace.
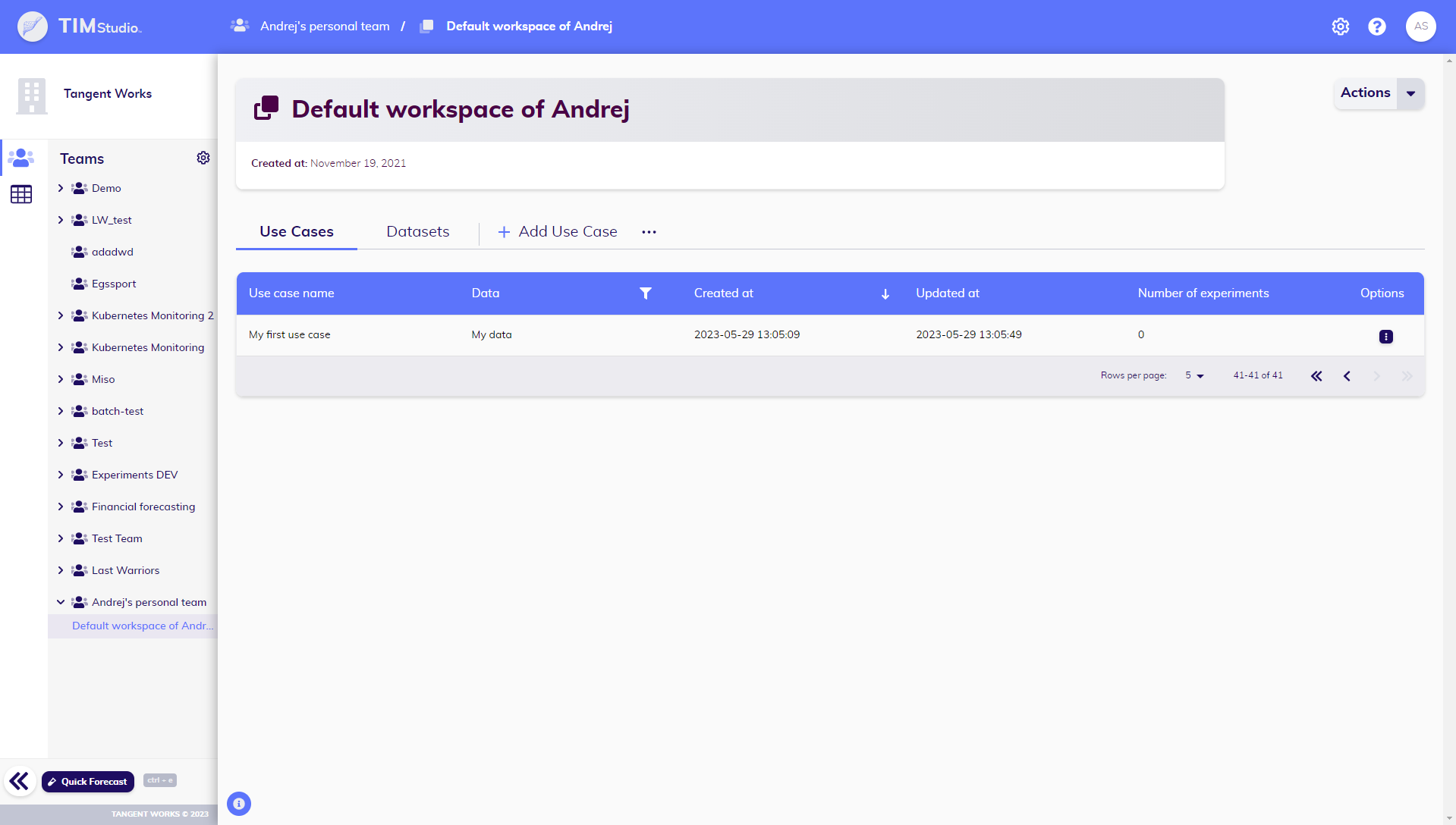
The default workspace shares all the same characteristics of a regular workspace, with two additional properties:
The default workspace cannot be deleted. It is always there, and though a user is not obligated to make use of it, it will keep existing withing their TIM environment.
The default workspace is on the default 'working directory' of the TIM Engine. If any requests are sent to TIM - from any platfrom, SDK or directly through the API - without specification of the relevant workspace, the resulting data will be handled in this default workspace, in the personal team of the user who made the request.
Workspaces in the navigation side bar
The navigation side bar that is situated to the left side of the screen (see below) shows a list of locations defined as a combination of a team and its associated workspaces.
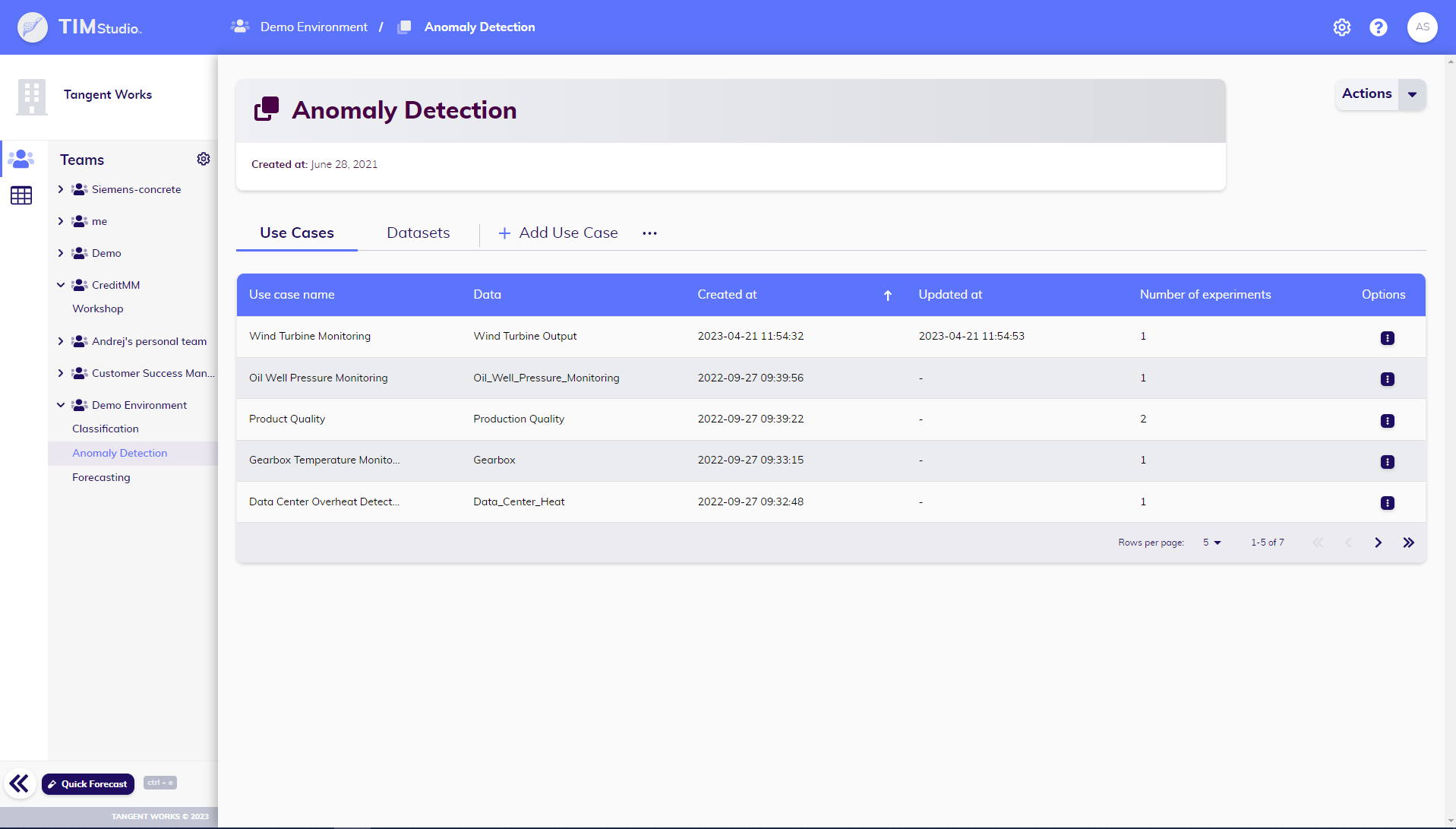
The side bar navigation gives a list of all locations that are available to a user. User may collapse teams that are not in use often and unfold only teams that user is interested in. Unfolding a team shows a list of workspaces of that team.
Workspace management
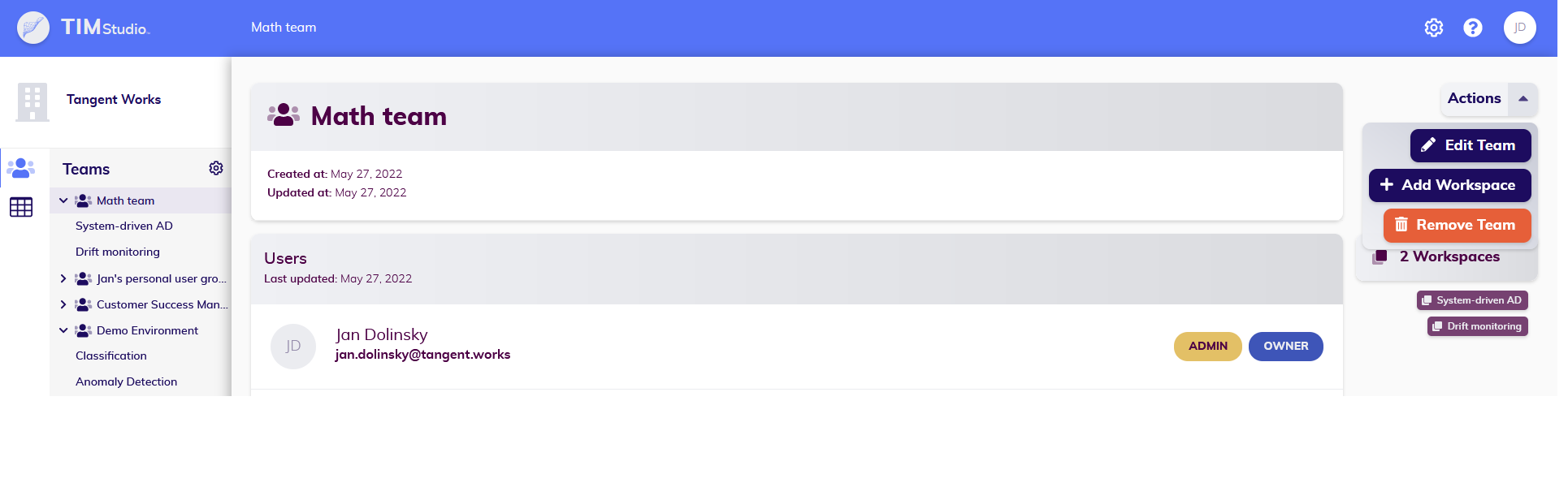
Adding: New workspace may be added by navigating to team detail page (see screenshot above) and clicking on "Add workspace" action.
Editing: Editing a workspace allows you to update its name and its description (see the screenshot below later in the text).
Deleting: Be careful with deleting a workspace: deleting a workspace will also permanently delete any data contained in this workspace. This includes all datasets and use cases contained in it, the experiments contained in these use cases and the ML jobs contained in these experiments (see the screenshot below later in the text).
Inside a workspace
There are two types of assets that sit in a workspace: datasets and their associated use cases. They have separate tabs.
Use cases tab
From this page, users can effortlessly browse the table to find a specific use case or a linked dataset of interest. They have the option to sort the table based on the time of creation or update, as well as view the number of experiments associated with each use case. Moreover, users can add a new use case or import it into the workspace. Additionally, they have the ability to edit, export, or remove an existing use case from the workspace using the options button.
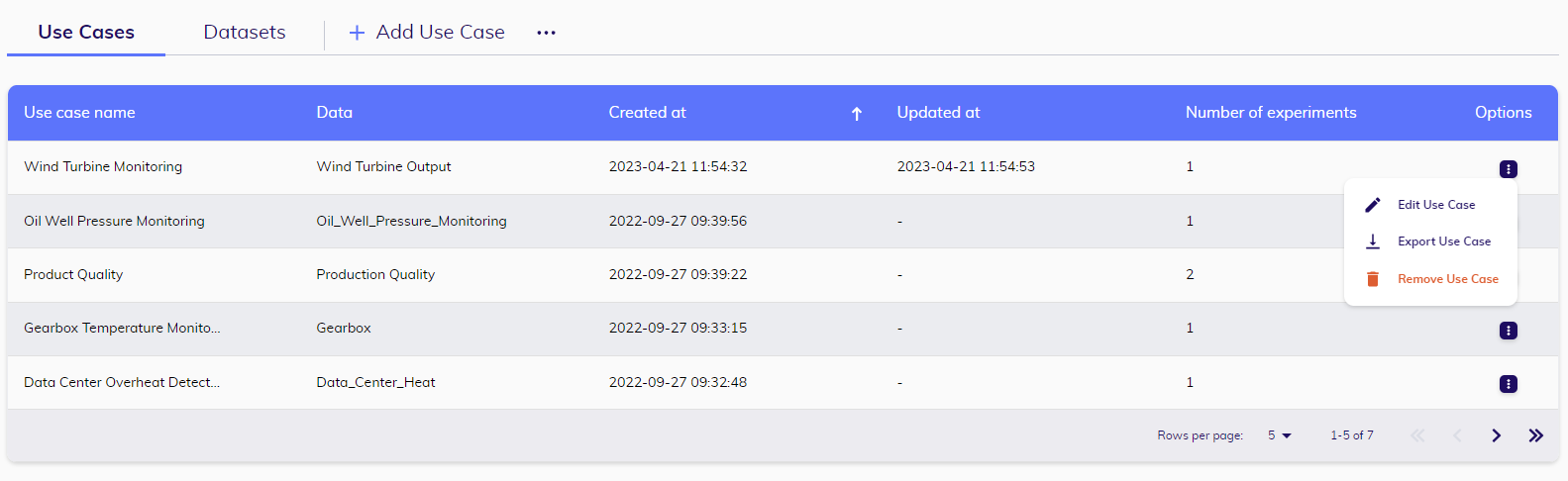
Adding: When creating a new use case, users can specify its name, description, business objective, business value, business KPI, and accuracy impact.
Editing: Users have the ability to modify a use case's name, description, business objective, business value, business KPI, and accuracy impact.
Removing: Please exercise caution when deleting a use case, as it will permanently erase all data associated with it. This includes experiments and ML jobs contained within the use case.
Importing: Importing a use case enables collaboration with individuals outside of the team or license. It also offers a convenient way to explore pre-existing templates from the Use Case Library.
Exporting: Users can export a use case to share their work with individuals external to the team or license.
Datasets tab
From this page, users can effortlessly browse the table to find a specific dataset of interest. They have the option to sort the table based on the time of creation or update, as well as view the number of rows and columns associated with each dataset. Moreover, users can add a new dataset into the workspace. Additionally, they have the ability to edit, update, download, show logs, or remove an existing dataset from the workspace using the options button.
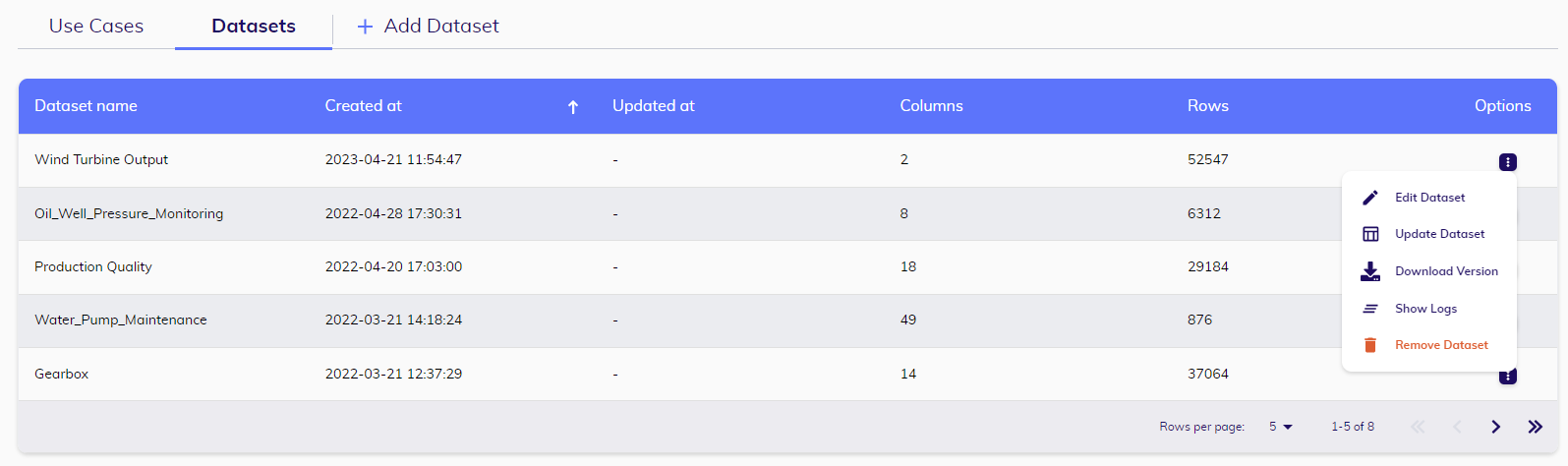
Adding: When adding a new dataset, users have the flexibility to specify various details such as the storage location, dataset name, time zone, and other technical aspects such as separators. These specifications allow users to customize the dataset management process according to their specific requirements and preferences.
Editing: Users have the ability to modify a dataset's name and description.
Updating: Users can update the dataset by making changes to its content or structure. Additionally, they can assign a version name to the updated dataset for better organization and tracking.
Downloading: Users have the option to download the provided dataset. They can save it locally to their device for further analysis, processing, or sharing purposes.
Showing logs: Users have the option to view the logs that provide information about the process of uploading the data. This allows users to track and monitor the progress, identify any potential errors or issues encountered during the upload process, and ensure a smooth and successful data upload experience.
Removing: It is crucial to exercise caution when deleting a dataset, as this action will permanently delete all associated use cases. This includes experiments and ML jobs that are contained within those use cases.