Operational IT Benefits
Scalable forecasting
Thanks to TIM’s efficiently implemented core mathematics, TIM is often much faster than typical AutoML solutions. TIM runs well on an average laptop, eliminating the need for users to invest in high-end hardware. Nevertheless, TIM’s cloud architecture is designed to scale, using computational resources in a cost-efficient way. The image below visually illustrates TIM’s single API architecture.
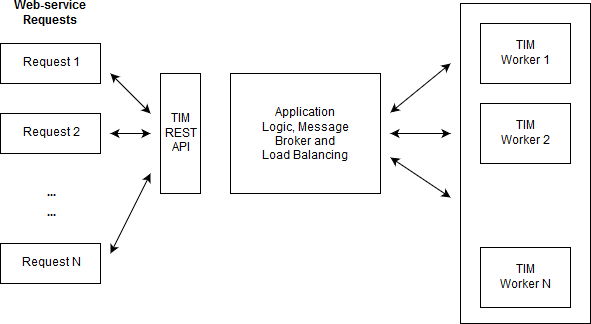
TIM provides a single API that supports a comprehensive set of machine learning operations, from model forecasting to InstantML and anomaly detection.
The application is designed to scale with the incoming number of requests by means of variable number of workers. Extra workers can be called immediately to absorb any sudden increase in demand and will automatically be discarded when demand slows down. In this way, TIM makes sure no redundant workers take up any valuable computer space.
A single scalable API
Developing a model and deploying it in production are significantly different. Most of the current platforms address this challenge by encapsulating all required software components in a container, including the model itself. Such a container is typically encapsulated through a REST (REpresentation State Transfer) API that exposes the model to the outside world.
This approach helps to narrow down the gap between model development and model deployment. At the same time, it implies some limitations that are worth pointing out, especially when it comes to building large-scale forecasting systems in a cloud infrastructure. A container must be up and running each time its model is required.
In large-scale scenarios where many models are used, this means a great amount of containers continually have to be kept active and callable via their individual API’s. This obviously brings about a considerable cost. In deployment, models are typically used either on an ad-hoc basis or on a regular schedule and each forecast typically takes millisecond to seconds to calculate. The rest of the time the container is idly running. It is clear to see this is not an efficient way of working.
TIM’s architecture is designed to work differently. TIM also has a single API which facilitates all possible types of requests (model training, forecasting, anomaly detection…). This API is kept up and running at all times and is used to call any desired model. In the background, TIM runs a few workers that can facilitate all possible requests. One of these requests is interpreting any previously built model. The number of active workers automatically scales with the number of incoming requests. Because only one single API is implemented, TIM is very easy to use and less error prone than systems with more complex interfaces.