Forecasting Process
Using Tangent is straightforward—all you need is time series data and a configuration. Tangent processes this input through a Multi-Situational Layer, which identifies the specific modelling scenarios required. This process automatically generates a model and forecast, with the resulting models being stored in what is known as the "Model Zoo"—a dynamic repository of models optimized for different forecasting conditions.

1. Data
data parameter | time_series | build_model | predict | auto-forecast | default value |
|---|---|---|---|---|---|
timestamp_column | ☑ | ☐ | ☐ | ☑ | first timestamp column |
group_key_columns | ☑ | ☐ | ☐ | ☑ | [] |
training_rows | ☑ | ☐ | ☐ | ☑ | All records in the dataset |
prediction_rows | ☑ | ☐ | ☐ | ☑ | None |
columns | ☑ | ☐ | ☐ | ☑ | All columns |
imputation | ☑ | ☐ | ☐ | ☑ | linear for gaps no longer than 6 samples |
☑ | ☐ | ☐ | ☑ | automatic |
2. Configuration
We have put a lot of effort into creating a fully automatic model building engine. Still, even against our best efforts, sometimes some models do not get the highest possible accuracy. However, users can ensure that even the toughest dataset can be modeled properly by toying with the algorithm's exposed parametrization.
The following subsections go through all of the available settings of Tangent Forecasting. The table below shows all configuration parameters available for different job types.
configuration parameter | build-model | predict | auto-forecast | default value |
|---|---|---|---|---|
☑ | ☑ | ☑ | sample + 1 | |
☑ | ☑ | ☑ | sample + 1 | |
☑ | ☑ | ☑ | determined from dataset end | |
☑ | ☑ | ☑ | automatic | |
☑ | ☐ | ☑ | first non-timestamp column | |
☑ | ☐ | ☑ | none | |
☑ | ☐ | ☑ | none | |
☑ | ☐ | ☑ | automatic | |
☑ | ☐ | ☑ | automatic | |
☑ | ☐ | ☑ | True | |
☑ | ☐ | ☑ | automatic | |
☑ | ☐ | ☑ | True | |
☑ | ☐ | ☑ | automatic | |
☑ | ☐ | ☑ | polynomial, time_offsets, identity, intercept, rest_of_week, piecewise_linear, exponential_moving_average, periodic | |
☑ | ☐ | ☑ | automatic | |
☑ | ☐ | ☑ | 90% | |
☐ | ☐ | ☑ | all |
prediction_from
This setting complements prediction_to and allows skipping the first samples in the forecasting horizon. It consists of a baseUnit (one of Day, Hour, Minute, Second and Sample) and a value (non-negative integer). If not set, Tangent will default to one Sample ahead, not skipping anything.
"prediction_from": {
"baseUnit": "day",
"value": 1
}prediction_to
This setting complements prediction_from and serves to define the forecasting horizon.. It consists of a baseUnit (one of Day, Hour, Minute, Second and Sample) and a value (non-negative integer). If not set, Tangent will default to one Sample ahead, not skipping anything.
"prediction_to": {
"baseUnit": "day",
"value": 1
}Defining Prediction_to with day, hour, minute and second
When setting up forecasts, users often want to predict the entire next day or specific future time periods without having to manually calculate the number of samples needed. The prediction_to parameter in Tangent allows you to specify this in an intuitive way, using a relative notation based on the last target observation.
Here’s how it works:
Day+1: If you setprediction_totoDay+1, Tangent will forecast all the way up to the end of the next day, regardless of when the last observation occurred on the current day. It automatically considers the next day as the forecasting horizon.Day+0: Forecasts up to the end of the current day.Hour+1: Forecasts up to the end of the next hour from the last observation.Hour+0: Forecasts up to the end of the current hour.QuarterHour+1: Forecasts up to the end of the next 15-minute interval.QuarterHour+0: Forecasts up to the end of the current 15-minute interval.
Examples:
| Last Target Observation | Forecasts All Samples Up To |
|---|---|---|
| 28-01-2012 22:13:56 | 29-01-2012 23:59:59 |
| 28-01-2012 22:13:56 | 28-01-2012 23:59:59 |
| 28-01-2012 22:13:56 | 28-01-2012 23:59:59 |
| 28-01-2012 22:13:56 | 28-01-2012 22:59:59 |
| 28-01-2012 22:13:56 | 28-01-2012 22:29:59 |
| 28-01-2012 22:13:56 | 28-01-2012 22:14:59 |
data_alignment
The data_alignment setting allows you to define how data is aligned at the end of the dataset, which is particularly useful for backtesting. This setting lets you specify the timestamp of the last target observation (timestamp) from which the rolling window is applied and production forecasts are generated. If you don't specify this timestamp, Tangent will use the last non-missing target timestamp from the original data.
Key Points:
The lastTargetTimestamp must be later than any out-of-sample records.
You can also specify the alignment of other variables (except the target) relative to the last non-missing target timestamp.
If you don't provide an alignment for a variable, Tangent will use the data_alignment from the original data. This means it will maintain the original time difference between the last non-missing timestamp of the variable and the target.
"data_alignment": [
{'column_name': 'Sales','timestamp': '2021-01-31 00:00:00Z'},
{'column_name': 'inventory','timestamp': '2021-01-30 00:00:00Z'}
]prediction_boundaries
For some datasets, values outside certain boundaries do not make sense - e.g. negative values for energy production. Tangent tries to figure these out automatically, but there is an option to override these detected values. Both the lower and upper boundaries should be real values. It might be useful to turn prediction boundaries off for datasets with a visible trend. Learn more about the purpose of this parameter and how to use it in the dedicated section on prediction intervals.
"predictionBoundaries": {
"type": "Explicit",
"maxValue": 1000,
"minValue": 0
}target_column
This setting defines the column (given by its name) that contains the target variable for the forecast.
"target_column": 'sales'categorical_columns
This setting defines which columns (given by their names) that contain categorical variables.
"categorical_columns": ['store_type','promotion']holiday_column
This setting indicates whether there is a holiday or special event to consider.
"holiday_column": 'holiday'target_offsets
This setting determines how the target variable is used in the model-building process, specifically regarding its time-based offsets. This setting directly impacts the balance between model accuracy and training time.
Available Options:
None:
No target offsets are used in the models. The target variable is taken as it is, without any time shifts.
Common:
Models use common target offsets that apply within a single day. This is a general approach that balances accuracy and efficiency.
Close:
Models use the closest possible target offsets. This option focuses on accuracy for short-term predictions by utilizing recent target values, but it increases training time.
Combined:
For the first two days after the last target timestamp, the models use close offsets for higher accuracy. For the remaining forecast horizon, they switch to common offsets to save on training time.
Important Considerations:
Training Time vs. Accuracy: Using close offsets (which rely on recent target values) can significantly increase the time it takes to train the model. For long-term forecasts, using close offsets may not improve accuracy enough to justify the extra time spent in training.
Use Case Specificity: In some scenarios, such as with soft sensors that simulate the target variable from predictors alone, target offsets may not be necessary.
Linked Settings:
predictor_offsets: If you set
predictorOffsetsto close, thentargetOffsetscan only be set to None or close.allow_offsets: If
allow_offsetsis set to False,targetOffsetswill automatically be set to None, meaning no offsets will be used for the target variable.
Default Settings:
Combined: This is the default setting in most cases, combining close offsets for short-term accuracy with common offsets for longer forecasts.
Close: If
predictor_offsetsare set to Close, the default fortarget_offsetswill also be close.None: If
allow_offsetsis set to False, the default fortarget_offsetswill be None.
Special Note:
When using Common, Close, or Combined target offsets, Tangent optimizes the selection of offsets within a day to reduce training time. This can lead to small differences in models for the same prediction horizon, depending on how far into the future you’re forecasting (e.g., models for S+1 might differ slightly between a forecast horizon of S+5 and S+10).
"target_offsets": 'close'predictor_offsets
The predictor_offsets setting determines how predictor variables are used in the model-building process, specifically concerning their time-based offsets. This setting impacts how Tangent selects and utilizes predictors, balancing between efficient model building and accuracy.
Available Options:
Common:
Models use common predictor offsets that apply within a single day. Predictors are selected in batches by day, which is efficient and balances accuracy with faster model building. This is the default setting.
Close:
Each model is trained individually using the closest possible offsets for both predictors and the target (if target offsets are allowed). This option prioritizes accuracy, especially for short-term forecasts, by focusing on the most recent predictor values. However, it significantly increases model-building time.
Important Considerations:
Model Building Time: Setting
predictorOffsetsto close will increase the time required to build models, as each situation within the forecasting horizon is trained individually. This can be appropriate for short prediction horizons where not all predictors are available throughout the entire forecasting period.Accuracy vs. Efficiency: Common offsets provide a good balance between accuracy and efficiency by using a generalized approach, while close offsets are more precise but at the cost of longer training times.
Default Setting:
Common:
The default setting is common, where predictors are selected in daily batches. This approach is generally faster and sufficient for most forecasting needs.
Special Note:
Even if only the target variable is available, setting predictorOffsets to close can affect the models due to the individual training process. Close offsets are useful when high precision is required, especially in scenarios with short prediction horizons or when predictor availability is inconsistent.
"predictor_offsets": 'common'allow_offsets
The allow_offsets setting is a boolean option that controls whether time-based offsets of predictors are used in the model-building process. This setting impacts several aspects of how the model is constructed and which features are included.
Key Functions of allow_offsets:
Offsets Usage:
True:
Time Offsets transformations of predictors, Exponential Moving Averages (EMA), and Simple Moving Averages (SMA) can be used in the model.
False:
No time offsets, EMA, or SMA will be used in the model.
These transformations will be automatically excluded, and there is no need to manually deselect them in the transformations configuration.
Piecewise Linearity:
False: The piecewise linearity transformation will only use predictors that are available at the exact timestamp being forecasted.
offset_limit parameter:
If
allowOffsetsis set to false, the explicit offset_limit parameter must be set to 0, ensuring that no offset-related features are included in the model.
Calendar transformations:
True or False: Calendar-based transformation (like day of the week or time of day) can still be included in the model, regardless of the
allowOffsetssetting. These features are derived directly from the forecasted timestamp and do not depend on time offsets.
"allow_offsets": Trueoffset_limit
The offset_limit setting determines the maximum historical range that time-based offsets of predictors can cover in the model-building process. This setting plays a crucial role in defining which time-offset features are included in the model and how far back in time the model will consider predictor data.
Key Functions of offset_limit:
Offsets Usage:
Explicit Value:
Definition: The
offsetLimitis a negative number that specifies how far into the past offsets can go. For example, a value of-10means the model will only consider offsets that are within 10 time units before the last observation.
Automatic Determination:
If no explicit value is set, Tangent will automatically determine the appropriate offset limit based on the data and the modeling requirements.
Feature Inclusion:
Time Offsets: Only offsets that fall within the defined range will be considered during model building.
EMA , SMA, and piecewise linearity: These transformations will only be applied if the closest available offset of the predictor is within the specified offset_limit.
Interaction with allow_offsets:
False:
If
allow_offsetsis set to false, theoffset_limitmust be set to 0, which prevents the use of any time offsets in the model, ensuring that only current-time data is used.
Calendar transformations:
Calendar-based transformations (such as day of the week or time of day) are not affected by the
offset_limitsetting. These features are derived directly from the forecasted timestamp and do not rely on historical offsets, meaning they will still be included in the model regardless of theoffset_limitvalue.
normalization
When normalization is on, predictors are scaled by their mean and standard deviation. Switching normalization off may help to model data with structural changes. If not provided or set to automatic, Tangent will decide automatically.
"normalization": Truemax_feature_count
Sets the max number of features in each model in the model zoo; Tangent finds automatically it based on the sampling period of the dataset.
"max_feature_count": 20transformations
Tangent tries to enhance the model building process with artificially created featured derived from the original predictors. The following transformations are available (those in bold are used by default).
"transformations": ['exponential_moving_average', 'rest_of_week', 'periodic',
'intercept', 'piecewise_linear', 'time_offsets', 'polynomial',
'identity', 'simple_moving_average', 'month', 'trend',
'day_of_week', 'fourier', 'public_holidays', 'one_hot_encoding']
daily_cycle
This setting is a boolean option that determines whether to use an individual model-building approach for different times within a day. Enabling this setting is beneficial if the dynamics of the underlying problem vary throughout the day. If turned off, a single model will be built for all timestamps, regardless of time-specific variations. This setting decides whether models should focus on specific times of the day (such as hours, quarter-hours, etc.), which Tangent identifies using autocorrelation analysis. Learn more about the importance of this parameter in the dedicated section on daily cycle.
"daily_cycle": Falseconfidence_level
This setting defines the confidence level for prediction intervals. A symmetric prediction interval with a specific confidence level given in percentage will be returned for all predictions. Learn more about the purpose of this parameter and how to use it in the dedicated section on prediction intervals.
"confidence_level": 90backtest
This setting determines which types of forecasts should be returned. The ‘production’ option only returns the production forecast, the ‘out_of_sample’ option also produces out-of-sample forecasts, and the ‘all’ option also delivers in-sample forecasts. Learn more about backtesting in the dedicated section.
"backtest": "all"3. Multi-Situational layer
When building a model, Tangent tries to automatically recognize all situations that might require (or benefit from) a specific model.
This approach allows Tangent to create simple models for simple situations - like solar forecasting at night (where production is zero) - or sophisticated models when the situation requires complexity - like trading at the opening minute.
By identifying and exploiting similarities between situations, Tangent minimizes redundant complexity, focusing only on the necessary details. This ensures fast and efficient model building and forecasting.
Usually, many different situations occur. Tangent creates a separate model for each situation optimized to the situation's conditions. These models are then combined into a collective repository known as the Model Zoo. Every time a forecast is requested:
Tangent recognizes the current situation automatically
Assesses the appropriateness of each model for the current situation
Builds or exploits tailored model for the situation
Combines the models into a model Zoo to generate a multi-step ahead forecast.
A situation in this context is defined by:
Forecast Horizon Distance
Definition: How far into the future you need the forecast.
Explanation: This gap determines where the timestamp falls within the forecasting horizon. Tangent creates a separate model for each point in the forecasting horizon because predicting further into the future is generally more challenging and requires different model complexities.
Example: Forecasting wave height one hour ahead may require a simple moving average model while forecasting wave height one day ahead could take into account correlations between of wind directions, wave height and temperature.

Time of Day
Definition: The specific time of day for the desired forecast.
Explanation: Some datasets exhibit a daily cycle, meaning they show regular patterns throughout the day influenced by socio-economic factors. It might be more difficult to forecast events at certain times, like noon, compared to other times, like midnight. Tangent automatically detects these daily cycles and creates separate models for different times of the day.
Example: Energy consumption patterns might differ significantly between daytime and nighttime, necessitating different models for these periods.

Predictor Data Availability
Definition: What predictor data is available at the time of forecasting.
Explanation: Time series analysis often involves using offsets (lags) of predictor data. Due to irregularities in data collection, these offsets can vary. Tangent Works distinguishes between situations where different offsets of predictor data are available. It prioritizes using the most recent data and creates new models when necessary to exploit closer offsets or to adjust when certain offsets are no longer available.
Example: If a model used a 24-hour lag of a predictor, but now only a 22-hour lag is available, Tangent Works will build a new model to make the best use of the available data.

Tangent will then process this information through a multi-situational layer, identify the appropriate modelling process, and automatically generate a model along with a forecast.
4. Model building
Tangent follows best practices in time-series modeling to maximize accuracy while minimizing the time required. The dedicated section on model building outlines the four stages of creating meaningful features and balancing the trade-off between bias and variance.
5. Forecast
The forecasting output from Tangent is a detailed table that provides multiple forecasts for various timestamps. Each entry reflects a different model selected from the Model Zoo. Understanding how to interpret and use this output is key to making informed decisions, whether you’re evaluating model performance through backtesting or making real-time forecasts in production.
Structure of the Forecasting Output Table
The table generated by Tangent includes several important columns:
column name | description |
|---|---|
timestamp | The exact time for which the forecast was made. |
date_from | The date when the forecast was initiated, either in backtesting or production. |
time_from | The time when the forecast was initiated, either in backtesting or production. |
target | The actual observed value at the given timestamp. If unavailable, it is marked as missing. |
forecast | The predicted value for the corresponding timestamp. |
forecast_type | Indicates the forecast type: 0 for in-sample backtest, 1 for out-of-sample backtest, or 2 for production forecast. |
relative_distance | The time distance from the forecast initiation, expressed in days (e.g., D+7) or samples (e.g., S+5). |
model_index | The index of the model from the Model Zoo used to generate the forecast. |
samples_ahead | The number of samples ahead of the last available target, showing how far into the future the forecast extends. |
lower_bound | The lower end of the prediction interval, indicating the range of uncertainty. |
upper_bound | The upper end of the prediction interval, indicating the range of uncertainty. |
bin | Groups forecasts into continuous signals for easier plotting and analysis. |
Why Multiple forecasts for single timestamp?
Tangent generates multiple forecasts for a single timestamp because it selects the best model from its Model Zoo based on the data available at the time of forecasting. This process happens in two main scenarios:
In Real-Time Forecasting:
Tangent dynamically picks the most suitable model depending on the current data and the forecasting horizon. For instance, if you request a forecast for "2019-03-03 15:00:00" at "2019-03-02 07:05:35," Tangent might choose a model that was optimized for the 07:00 data from one day ahead.
This means that even though the target time (15:00 on March 3rd) is the same, the model used might differ depending on when the forecast was made.
During Backtesting:
When Tangent is evaluating model performance on historical data, it can generate multiple forecasts for the same timestamp by simulating different scenarios. For example, it might simulate what would have happened if a forecast had been made at various points leading up to the target time.
This results in several forecasts for the same timestamp, each reflecting different data availability and modeling conditions.
How Tangent Processes These Multiple Forecasts
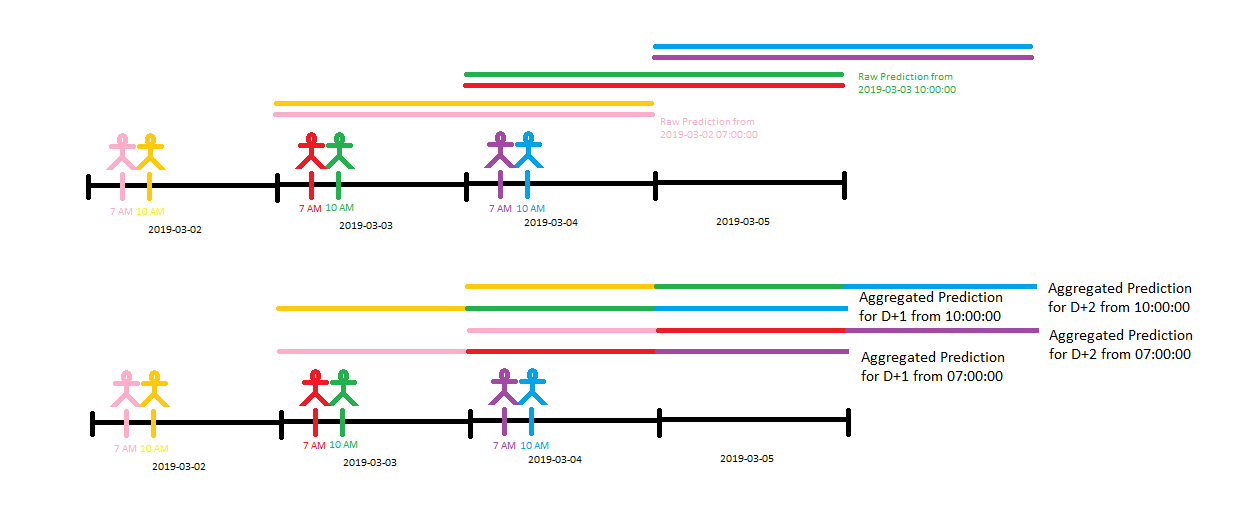
The image accompanying this explanation visually represents how Tangent handles these multiple forecasts.
Top Part: Raw Predictions:
The top part of the image shows colored lines, each representing a forecast made at different times (e.g., 7 AM and 10 AM on March 2nd and 3rd). These lines stretch across the dates they predict, such as 7 AM or 10 AM on March 4th.
This illustrates that Tangent produces multiple forecasts for the same future timestamp, but each forecast is generated from a different starting point in time, reflecting the data available when that forecast was made.
Bottom Part: Aggregated Predictions:
The bottom part of the image shows how Tangent combines these multiple raw forecasts into a single, aggregated prediction.
Instead of relying on just one forecast, Tangent merges all available forecasts for a particular future time. This process ensures that the final prediction is more accurate and reliable, as it incorporates the most recent data and considers different perspectives.
This feature ensures Tangent uses the most accurate and relevant data to generate your forecasts.
How to Use the Forecasting Output
To get the most out of the Tangent forecasting output, apply these filters to focus on the information that matters most:
All forecasts with forecast type Production:
Purpose: Focuses on forecasts that are being used in real-time operations.
Best For: Monitoring how well Tangent’s models perform in live situations.
All forecasts:
Purpose: Provides an overall view of model performance.
Best For: General assessment, though not ideal for creating plots due to overlapping data.
Forecasts for a specific bin:
Purpose: Helps create smooth, continuous signals by grouping forecasts that don’t overlap.
Best For: Visualizing trends over time.
Forecasts for a specific number of samples ahead:
Purpose: Shows how the accuracy of forecasts changes as you look further into the future.
Best For: Analyzing how forecast reliability decreases over time, especially during backtesting.
Forecasts by Specific time_from and relative_distance:
Purpose: Useful in scenarios where you need to forecast at the same time each day.
Best For: Assessing how accurate daily forecasts are, like predicting daily sales or energy use.
Forecasts from a specific date_from and time_from:
Purpose: Allows you to see what a particular forecast would have looked like historically.
Best For: Reviewing past forecasts to understand how well models performed.
Forecasts by model_index:
Purpose: Helps you see which models contributed to a forecast and why it turned out the way it did.
Best For: Understanding the origins of forecasts and improving model selection.
5. Model Zoo
The Model Zoo is a dynamic repository where all the individual models created during Tangent’s multi-situational analysis are stored and managed. It plays a crucial role in ensuring that the right model is applied to the right situation, optimizing both accuracy and efficiency.
By leveraging the Model Zoo, Tangent ensures that the most appropriate model is always used, delivering accurate and reliable forecasts tailored to the specific needs of each situation, such as the time of forecasting, the forecasting horizon, and data availability.
How the Model Zoo Works:
Model Collection: During the multi-situational layer, Tangent builds separate models for each identified situation. These models are then stored in the Model Zoo.
Automatic Situation Recognition: When a forecast is requested, Tangent automatically recognizes the current situation based on factors like the time of forecasting, the forecast horizon, and the availability of predictor data.
Model Selection and Combination: Tangent assesses the suitability of each model in the Model Zoo for the current situation. It either selects an existing model or builds a new one if necessary. The selected models can also be combined to generate a comprehensive, multi-step ahead forecast.
Continuous Optimization: The Model Zoo evolves continuously as new data and situations are encountered. Models are updated or replaced to ensure they remain accurate and relevant.
Key Information Managed in the Model Zoo:
sampling_period: The time interval at which data is collected.
average_training_length: The average length of all datasets used to build the models within the model Zoo.
difficulty: A measure of how challenging it is to model the data. It ranges from 0 to 100 percent and is calculated as 1 minus the ratio of the explained variance to the original variance when using a simple regression model. Completely random data will have difficulty close to 100, whereas highly correlated data will have a difficulty close to 0.
target_column: The name of the target variable.
holiday_column: Public holiday data used to enhance modelling.
prediction_boundaries: Limits that constrain forecasts within specific ranges.
daily_cycle: Indicates whether different times of the day are considered.
confidence_level: The confidence level of prediction intervals.
in_sample_rows and out_of_sample_rows: Data ranges used for training and validation.
variable_properties: Detailed information about each predictor.
min_values and max_values: The range of values observed for predictors.
importance: The contribution of each predictor to the model.
data_from: For each of the original predictors, an integer value is returned that signifies how far into the predictor's history the model potentially looks (expressed in samples) when predicting a specific timestamp. This indicates what the model needs, and avoids the need to transfer unnecessary loads of data when predicting with Tangent.
aggregation: How variables were aggregated (e.g., mean, sum). This is related to time_scale, as the sampling period to aggregate to is defined there.
models: The collection of models tailored for specific situations.
prediction_intervals: The range of uncertainty around predictions. This is related to the prediction_boundaries.
daytime and forecast_horizon: Unique identifiers for models based on the time of day and forecast horizon.
variable_offsets: The historical data needed for each predictor.
last_target_timestamp: The most recent data point used in the model.