Backtesting
Backtesting is a crucial step in evaluating how well a model might perform in real-world scenarios. It involves building a model on a set of historical data—referred to as the in-sample period—and then testing it on a separate part of the historical data—known as the out-of-sample period. This section explains the parameters that influence backtesting and its methodology while using Tangent.
Data Alignment
When Tangent produces a forecast, it starts from the end (i.e., the last timestamp) of the target variable. The length of the forecast and the number of observations to skip can be controlled using the Prediction To and Prediction Form parameters.
Tangent considers the availability and alignment of other predictors. Some predictors might be available beyond the target variable's range, while others might lag behind. Tangent automatically adjusts to create models that utilize all available data effectively.
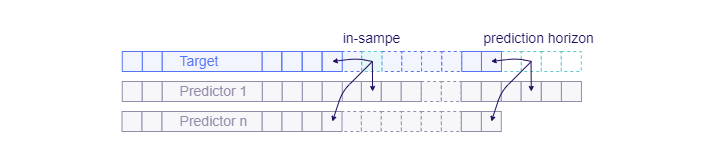
During backtesting, data alignment doesn’t need to match the alignment used in production. For example, during backtesting, all predictors might align perfectly with the target variable, while in production, some predictors might have different availabilities. This is depicted in the images below:

All predictors are aligned with the target during backtesting

Predictor 1 is available throughout the entire prediction horizon
To allow for this, it is possible to set data alignment in the job configuration. The last target observation can be shifted, affecting which timestamps are used for forecasting and how the rolling window is applied. You can also set alignments for other (non-target) variables relative to the last target observation. If no specific alignment is provided for a variable, Tangent uses the alignment from the original data.
Note: Setting a new alignment may result in no forecasts being generated for certain timestamps if the required data is unavailable at the end of the dataset.
Copying the "situation"
When performing forecasting on the historical part of a dataset, the relative shape of predictors and targets potentially does not correctly represent a real situation, since for every target observation, all predictor observations are typically available as well (not considering missing observations). TIM is built to recognize this and recreates the same situation as observed at the end of the dataset. That way the historical forecast is ensured to produce a similar accuracy to the one expected to achieve when the production forecast can be evaluated.
Historical Forecasting with Model Zoo
To make this work, Tangent exploits the fact that each of the samples in the forecasting horizon is forecasted with a different model from the Model Zoo. Tangent remembers these models, and when creating a forecast on the historical part of the data, uses the same models in the same order. If a model cannot be evaluated, NaN is returned. This might happen if there are missing data around that part of the dataset.
Model Utilization in Backtesting
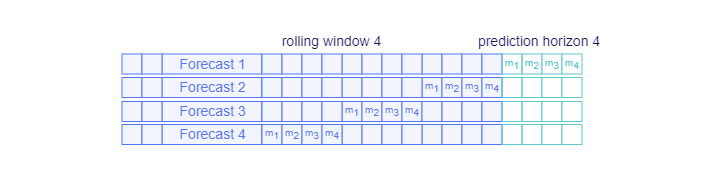
Using the rolling window parameter
A rolling window controls the points from which the forecast on historical data is made. The first point is exactly "rollingWindow" observations distanced from the last target timestamp. It then "rolls" back over the data with this same distance until it reaches the start of the dataset. If the rolling window is smaller than the prediction horizon, the in-sample forecasts will overlap - this will cause the output table to contain multiple forecasts for the same timestamp.
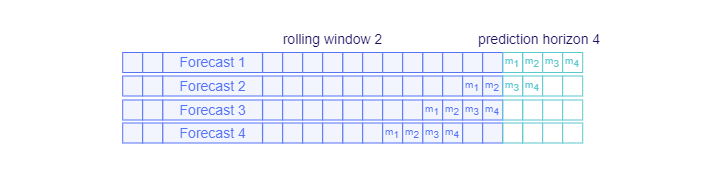
Rolling Window Forecasting
The default rolling window for non-daily cycle data matches the prediction horizon (predictionTo). The default rolling window for daily cycle data is one day.
Backtesting with daily cycle data
Changing the rolling window for daily cycle data is tricky, because models used for producing the production forecast are built for a specific time of day. This means that they will most likely not be able to evaluate forecasts, if the rolling window would be changed to some value that is not a divisor or a multiple of a day. This also means that if a daily cycle dataset ends at 13:00, but the goal is to backtest how Tangent would perform at 12:00, the last observations of the dataset should be removed accordingly. This applies still even if the Model Zoo already contains models built to forecast from 12:00, because the backtesting prioritizes using models that the production forecast was produced with, and the production forecast would be done from 13:00 in this case.
Understanding the in-sample and out-of-sample settings
These settings serve a user to mark parts of the data that the model should be built on, and parts on which the model should be evaluated. This does not influence the position of the rolling windows; hey will stay the same, but will be cut in places where the forecast (either in-sample or out-of-sample) is not desired.

In-Sample and Out-of-Sample Data Settings